如果你想把一只猫肢解了来研究它是怎么工作的,那么首先你要得到一只不工作的猫。-- 道格拉斯·亚当斯
“我要怎么按日期来统计记录条数?”对于数据库程序员来说,这是一个最基本的任务例子。它的解决方案在任何SQL入门介绍中都会出现,因为它包含了SQL最基本的语法:
EAV/intro/count.sql
SELECT date_reported, COUNT(*) FROM Bugs GROUP BY date_reported;
然而,这个简单的解决方案需要两个假设。
- 所有的值都存在同一列中,比如Bugs.data_reported。
- 数据类型是可以比较的,因而GROUP BY可以通过比较两个值是否相等来分组。
假如这些假设不能满足呢?如果日期存储在date_reported或者report_date,或者其他任何列且每条记录的列名都不相同呢?如果日期的格式各式各样,而数据库无法简单地比较两个日期又该如何呢?
如果你在使用“实体—属性—值”反模式,就会遇到前面说的以及其他的一些问题。
6.1 目标:支持可变的属性
可扩展性是所有软件项目设计中最普遍的一个目标。我们都想设计出一个不需要过多修改,甚至不需要修改就能适合将来需求变更的软件。
这并不是一个新的课题,自1970年E. F. Codd在他的A Relational Model of Data for Large Shared Data Banks[Cod 70]一文中第一次介绍了关系模型的概念以来,相似的关于关系数据模型不灵活性的争论就一直在持续。
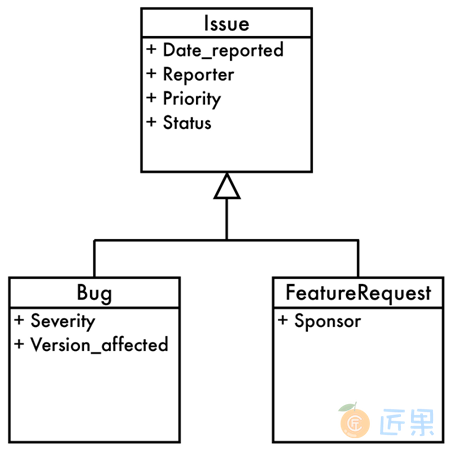
通常来说,一张表由一些属性列组成,表中的每一条记录都使用这些列,因为每条记录表示的都是相似的对象实例。不同的属性集合表示不同的对象,因而就应该用不同的表来区分。
但是,在现代面向对象的编程模型中,不同的对象类型可能是相连的。比如,多个对象都可能是从同一个基类派生而来,它们既是实际子类的实例,也同时是父类的实例。我们可能想仅使用一张表来存储所有这些不同类型的对象,这样能方便进行比较和计算。但我们也需要将不同的子类分开存储,因为每个子类都有一些特殊的属性,和其他的子类甚至父类都不能共用。
我们继续使用Bugs数据库来举例。在图6-1中,Bug和FeatureRequest有一些公共属性,我们将其提炼为一个基类,称为Issue。每个事件都和一个报告它的人相关,同时也和一个产品相关,并且这个产品有个优先级用以比较。然而,Bug有一些独特的属性:产生错误的产品版本号和错误的级别。同样地,FeatureRequest也有自己的特有属性,比如,假设一个产品特性是和支持这一特性的开发赞助商相关的。
6.2 反模式:使用泛型属性表
对于某些程序员来说,当他们需要支持可变属性时,第一反应便是创建另一张表,将属性当成行来存储。图6-2中,属性表中的每条记录都包含三列。
- 实体:通常来说这就是一个指向父表的外键,父表的每条记录表示一个实体对象。
- 属性:在传统的表中,属性即每一列的名字,但在这个新的设计中,我们需要根据不同的记录来解析其标识的对象属性。
- 值:对于每个实体的每一个不同属性,都有一个对应的值。
比如,一个给定的Bug是一个实体对象,我们通过它的主键来标识它,它的主键值为1234。这个对象有一个属性status,Bug1234的status的值为NEW。
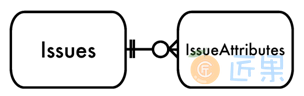
这样的设计称为实体—属性—值,简称EAV。有时也称之为:开放架构、无模式或者名—值对。
EAV/anti/create-eav-table.sql
CREATE TABLE Issues (issue_id SERIAL PRIMARY KEY );
INSERT INTO Issues (issue_id) VALUES (1234);
CREATE TABLE IssueAttributes (
issue_id BIGINT UNSIGNED NOT NULL,
attr_name VARCHAR(100) NOT NULL,
attr_value VARCHAR(100),
PRIMARY KEY (issue_id, attr_name),
FOREIGN KEY (issue_id) REFERENCES Issues(issue_id)
);
INSERT INTO IssueAttributes (issue_id, attr_name, attr_value)
VALUES (1234, 'product', '1'),
(1234, 'date_reported', '2009-06-01'),
(1234, 'status', 'NEW'),
(1234, 'description', 'Saving does not work'),
(1234, 'reported_by', 'Bill'),
(1234, 'version_affected', '1.0'),
(1234, 'severity', 'loss of functionality'),
(1234, 'priority', 'high');
通过增加一张额外的表,可以获得如下这些好处。
- 这两张表的列都很少。
- 新增的属性不会对现有的表结构造成影响,不需要新增列。
- 避免了由于空值而造成的表内容混乱。
这看上去是一个改良过的设计,然而,设计上的简单化并不足以弥补其造成的使用上的难度。
6.2.1 查询属性
假设你的领导想要每天获取一份Bug的报表,在传统的表结构设计中,Issues表中仅包含了很简单的属性列,比如date_reported,要根据日期查询Bug记录,只需要执行一句很简单的语句:
EAV/anti/query-plain.sql
SELECT issue_id, date_reported FROM Issues;
要使用EAV设计来做相同的事情,就需要先从表IssueAttributes中提取出属性列为date_reported的所有记录。查询操作更加啰唆,而且不够清晰:
EAV/anti/query-eav.sql
SELECT issue_id, attr_value AS "date_reported" FROM IssueAttributes WHERE attr_name = 'date_reported';
6.2.2 支持数据完整性
使用了EAV的设计,需要放弃很多传统的数据库设计所带来的方便之处。
6.2.3 无法声明强制属性
要让你的领导能够顺利地生成项目报表,需要确保date_reported这个属性有值。在传统的数据库设计中,可以很简单地通过在声明的时候加上NOT NULL的限制来确保该列的值不为空。
在EAV的设计中,每个属性对应IssueAttributes表中的一行,而不是一列。你可能需要一个约束来检查对于每个issue_id都存在这么一行,并且这行的attr_name列的值是date_reported。
然而,SQL没有任何类型的约束支持这么做。因而你必须通过编写外部程序的代码确保这点。如果找到一个没有提交日期的Bug记录,应该为它加上一个日期吗?那应该给它赋什么值?如果胡乱猜测一个值或者使用默认值,对于你老板报表的精确性来说有多少影响?
6.2.4 无法使用SQL的数据类型
你的老板告诉你他的报表有点问题,因为人们输入的日期格式各式各样,甚至有时是个字符串而根本就不是一个日期。在传统的数据库中,你可以通过将一列的类型声明为DATE来确保这种情况不会发生。
EAV/anti/insert-plain.sql
INSERT INTO Issues (date_reported) VALUES ('banana'); -- ERROR!
在EAV的设计中,IssueAttributes.attri_value列的数据类型就是一个单纯的字符串,从而才能仅用一列来适应任何可能的数据类型。因此,没有好办法来阻止无效数据的录入。
EAV/anti/insert-eav.sql
INSERT INTO IssueAttributes (issue_id, attr_name, attr_value) VALUES (1234, 'date_reported', 'banana'); -- Not an error!
有些人尝试扩展EAV的设计,为每一个SQL类型定义一个单独的attr_value列,不需要使用的列就留空。这可以让你使用SQL的数据类型,却使得查询变得更加恐怖:
EAV/anti/data-types.sql
SELECT issue_id, COALESCE(attr_value_date, attr_value_datetime, attr_value_integer, attr_value_numeric, attr_value_float, attr_value_string, attr_value_text) AS "date_reported"
FROM IssueAttributes WHERE attr_name = 'date_reported';
你可能需要添加更多的列来支持用户自定义的数据类型或者域(domain)。
6.2.5 无法确保引用完整性
在传统的数据库中,你可以定义一个指向另一张表的外键来约束某些属性的取值范围。比如,一个Bug或者事件的status属性应该是一张很小的BugStatus表中的一个值。
EAV/anti/foreign-key-plain.sql
CREATE TABLE Issues (
issue_id SERIAL PRIMARY KEY, -- other columns
status VARCHAR(20) NOT NULL DEFAULT 'NEW',
FOREIGN KEY (status) REFERENCES BugStatus(status)
);
在EAV的设计中,你无法在attr_value列上使用这种约束方法。引用完整性的约束会应用到表中的每一行。
EAV/anti/foreign-key-eav.sql
CREATE TABLE IssueAttributes (
issue_id BIGINT UNSIGNED NOT NULL,
attr_name VARCHAR(100) NOT NULL,
attr_value VARCHAR(100),
FOREIGN KEY (attr_value) REFERENCES BugStatus(status)
);
如果你像这样定义约束,那会强制表中每个属性的值都必须存在于BugStatus中,而不仅仅是status属性。
6.2.6 无法配置属性名
你老板的报表依旧非常不靠谱。你发现这些属性的命名不够清晰。有个Bug的属性叫做date_reported,但另一个Bug记录却把这个属性称作report_date。虽然两者都很清晰地表达了同样的意思。
既然如此,你又要如何计算每天的Bug数呢?
EAV/anti/count.sql
SELECT date_reported, COUNT(*) AS bugs_per_date
FROM (SELECT DISTINCT issue_id, attr_value AS date_reported
FROM IssueAttributes
WHERE attr_name IN ('date_reported', 'report_date')
)
GROUP BY date_reported;
你又如何得知某条Bug记录没有用其他的名字来定义属性呢?你又如何得知某条Bug记录没有将同一个属性存储了两遍?你又要如何阻止这样的错误发生?
有一个解决方案是将attr_name列声明成一个外键,并指向一张存储着所有可能出现的属性名的表。然而,这不支持在运行时定义的各种属性,即使那是EAV设计的一个非常普遍的使用方式。
6.2.7 重组列
当数据是存储在一张传统的表中时,从Issues表中获取一整行记录,并得到一个议题的所有属性是个很平常的需求。
| issue_id | date_reported | stats | 优先级 | 描 述 |
|---|---|---|---|---|
| 1234 | 2009-06-01 | NEW | HIGH | 存储无法运行 |
由于每个属性在IssueAttributes表里都存储在独立的行中,要想像上面那样按行获取所有这些属性就需要执行一个联结查询,并将结果合并成行。同时,必须在写查询语句的时候就知道所有的属性名称。下面的查询语句重组了上表展示的行:
EAV/anti/reconstruct.sql
SELECT i.issue_id,
i1.attr_value AS "date_reported",
i2.attr_value AS "status",
i3.attr_value AS "priority",
i4.attr_value AS "description"
FROM Issues AS i LEFT OUTER JOIN IssueAttributes AS i1
ON i.issue_id = i1.issue_id AND i1.attr_name = 'date_reported'
LEFT OUTER JOIN IssueAttributes AS i2
ON i.issue_id = i2.issue_id AND i2.attr_name = 'status'
LEFT OUTER JOIN IssueAttributes AS i3
ON i.issue_id = i3.issue_id AND i3.attr_name = 'priority';
LEFT OUTER JOIN IssueAttributes AS i4
ON i.issue_id = i4.issue_id AND i4.attr_name = 'description';
WHERE i.issue_id = 1234;
你必须使用外联结来进行查询,因为如果在所查询的这些属性中有任何一个不在IssueAttributes表中出现,则内联结会导致整个查询返回空记录。随着属性的数量不断增多,联结的数量也不断增长,查询的开销也成指数级地增长。
6.3 如何识别反模式
如果你听到项目团队发出了如下的疑问,很有可能就是使用了EAV反模式。
- “数据库不需要修改元数据就可以扩展。你还可以在运行时定义新的属性。”关系数据库不支持这种程度的灵活性。当某人声称能够设计一个可以任意扩展的数据库时,他基本上用的就是EAV的设计。
- “查询时我能用的最大数量的联结是多少?”如果你需要一个支持如此多联结的查询,并且联结的数量可能会达到数据库的限制时,你的数据库的设计可能是有问题的。而EAV的设计很有可能会导致这样的问题。
- “我想象不出怎么为我们的电子商务平台生成报告。我们需要雇一个顾问来做这事。”似乎很多现有的数据库驱动的软件使用EAV的设计来支持其强大的自定义能力,而这使得很多普通的报表查询变得极度复杂甚至不切实际。
6.4 合理使用反模式
在关系数据库中很难为EAV这个反模式正名,因为这就不得不放弃关系型范式的太多优点。但这不影响在某些程序中合理地使用这种设计来支持动态属性。
大多数应用程序仅仅在有限的几张表甚至于仅一张中需要存储无范式的数据,而其他的数据需求适用于标准的表设计。如果你明白在你的项目中使用EAV设计的风险和你要做的额外工作,并且谨慎地使用它,它的副作用会变得较小。但请一定要记住,那些富有经验的数据库顾问给出的报告显示,使用EAV设计的系统在一年以内就会变得极其笨重。
如果你有非关系数据管理的需求,最好的答案是使用非关系技术。这是一本关于SQL的书,而不是关于SQL选择的问题,因此我会简单地列出一些相关的技术。
- Berkeley DB是一个流行的Key-Value存储服务,非常容易被整合进入大部分程序。 http://www.oracle.com/technology/products/berkeley-db/
- Cassandra是一个分布式的面向列的数据库,由Facebook开发,并提交给了Apache项目。http://incubator.apache.org/cassandra/
- CouchDB是一个面向文档的数据库——一个分布式的Key-Value存储系统,使用JSON编码数据。http://couchdb.apache.org/
- Hadoop和HBase组装了一个开源的DBMS,借助于Google的MapReduce算法为分布式大数据量查询提供分结构数据存储。http://hadoop.apache.org/
- MongoDB是一个像CouchDB一样的面向文档的数据库。http://www.mongodb.org/
- Redis是一个文件导向的内存数据库。http://code.google.com/p/redis
- Tokyo Cabinet是一个Key-Value存储结构,结合了POSIX DBM、GNU GDBM或Berkeley DB。http://1978th.net/
很多其他的非关系数据库项目也在不断地涌现。然而,在传统数据库中使用EAV设计的劣势也体现在这些非关系数据库上。当元数据不具有固定格式时,再简单的查询都会变得非常困难。上层应用就需要花费更多的时间、精力来组织数据结构。
6.5 解决方案:模型化子类型
如果EAV对于你的程序而言是正确的选择,你仍然需要在执行这个设计之前重新审视一遍。通过对列进行一些虽然老式但很好的分析,很可能会发现你的项目的数据可以更方便地被模型化到一个传统的表里,同时也提供了更保险的数据完整性支持。
除去使用EAV,还有好几个方法来存储这样的数据。当子类型数量有限时,大多数解决方案都能很好地工作,并且你知道每个子类型的属性。哪个解决方案最合适依赖于你查询数据的方式,因此你应该具体案例具体分析。
6.5.1 单表继承
最简单的设计是将所有相关的类型都存在一张表中,为所有类型的所有属性都保留一列。同时,使用一个属性来定义每一行表示的子类型。在这个例子中,这个属性称作issue_type。对于所有的子类型来说,既有一些公共属性,但同时又有一些子类型特有属性。这些子类型特有属性列必须支持空值,因为根据子类型的不同,有些属性并不需要填写,从而对于一条记录来说,那些非空的项会变得比较零散。
这个设计的名字来源于Martin Flower的一本著作:Patterns of Enterprise Application Architecture[Fow03]。
EAV/soln/create-sti-table.sql
CREATE TABLE Issues (
issue_id SERIAL PRIMARY KEY,
reported_by BIGINT UNSIGNED NOT NULL,
product_id BIGINT UNSIGNED,
priority VARCHAR(20),
version_resolved VARCHAR(20),
status VARCHAR(20),
issue_type VARCHAR(10), -- BUG or FEATURE
severity VARCHAR(20), -- only for bugs
version_affected VARCHAR(20), -- only for bugs
sponsor VARCHAR(50), -- only for feature requests
FOREIGN KEY (reported_by) REFERENCES Accounts(account_id)
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
当程序需要加入新对象时,必须修改数据库来适应这些新对象。又由于这些新对象具有一些和老对象不同的属性,因而必须在原有表里增加新的属性列。可能会遇到一个很实际问题,就是每张表的列的数量是有限制的。
单表继承的另一个限制就是没有任何的元信息来记录哪个属性属于哪个子类型。在你的程序中,假如你知道有些属性并不适用于一个特定的行所表示的子类型对象,那么就可以忽略它们。但必须手动地跟踪哪些属性适用于哪些子类型。即使我们知道如果能用元数据在数据库中定义这些会更好,但也无能为力。
当数据的子类型很少,以及子类型特殊属性很少,并且你需要使用Active Record模式来访问单表数据库时,单表继承模式是最佳选择。
6.5.2 实体表继承
另一个解决方案是为每个子类型创建一张独立的表。每个表包含那些属于基类的共有属性,同时也包含子类型特殊化的属性。这个设计的名字来源于Martin Fowler的书。
EAV/soln/create-concrete-tables.sql
CREATE TABLE Bugs (
issue_id SERIAL PRIMARY KEY,
reported_by BIGINT UNSIGNED NOT NULL,
product_id BIGINT UNSIGNED,
priority VARCHAR(20),
version_resolved VARCHAR(20),
status VARCHAR(20),
severity VARCHAR(20), -- only for bugs
version_affected VARCHAR(20), -- only for bugs
FOREIGN KEY (reported_by) REFERENCES Accounts(account_id),
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
CREATE TABLE FeatureRequests (
issue_id SERIAL PRIMARY KEY,
reported_by BIGINT UNSIGNED NOT NULL,
product_id BIGINT UNSIGNED,
priority VARCHAR(20),
version_resolved VARCHAR(20),
status VARCHAR(20),
sponsor VARCHAR(50), -- only for feature requests
FOREIGN KEY (reported_by) REFERENCES Accounts(account_id),
FOREIGN KEY (product_id) REFERENCES Products(product_id)
);
实体继承设计相比于单表继承设计的优势在于提供了一种方法,让你能阻止在一行内存储一些和当前子类型无关的属性。如果你引用一个并不存在于这张表中的属性列,数据库会自动提示你错误。比如,severity列并不在FeatureRequests表中:
EAV/soln/insert-concrete.sql
INSERT INTO FeatureRequests (issue_id, severity) VALUES ( ... ); -- ERROR!
另一个使用实体继承表设计的好处便是,不用像在单表继承设计里那样使用额外的属性来标记子类型。
然而,很难将通用属性和子类特有的属性区分开来。因此,如果将一个新的属性增加到通用属性中,必须为每个子类表都加一遍。
没有元数据标记这些存储在自己表中的子类型相互之间有什么关系。那意味着,如果一个新来的程序员查看这些表定义,他只会注意到所有子类型的表中都有一些重复的列,但元信息没有告诉他任何有关这些表之间的关系,或者是否仅仅由于某种巧合,才使得这些表长得如此相似。
如果你希望不考虑子类型而在所有对象中进行过滤查找,问题会变得很复杂。如果想要将这件事情变得简单一点,就需要创建一个视图联合这些表,仅选择公共的列。
EAV/soln/view-concrete.sql
CREATE VIEW Issues AS SELECT
b.*, 'bug' AS issue_type
FROM
Bugs AS b
UNION ALL
SELECT
f.*, 'feature' AS issue_type
FROM
FeatureRequests AS f;
当你很少需要一次性查询所有子类型时,实体继承表设计是最好的选择。
6.5.3 类表继承
第三个解决方案模拟了继承,把表当成面向对象里的类。创建一张基类表,包含所有子类型的公共属性。对于每个子类型,创建一个独立的表,通过外键和基类表相连。这个设计的名称同样来自于Martin Fowler的书。
EAV/soln/create-class-tables.sql
CREATE TABLE Issues (
issue_id SERIAL PRIMARY KEY,
reported_by BIGINT UNSIGNED NOT NULL,
product_id BIGINT UNSIGNED,
priority VARCHAR (20),
version_resolved VARCHAR (20),
STATUS VARCHAR (20),
FOREIGN KEY (reported_by) REFERENCES Accounts (account_id),
FOREIGN KEY (product_id) REFERENCES Products (product_id)
);
CREATE TABLE Bugs (
issue_id BIGINT UNSIGNED PRIMARY KEY,
severity VARCHAR (20),
version_affected VARCHAR (20),
FOREIGN KEY (issue_id) REFERENCES Issues (issue_id)
);
CREATE TABLE FeatureRequests (
issue_id BIGINT UNSIGNED PRIMARY KEY,
sponsor VARCHAR (50),
FOREIGN KEY (issue_id) REFERENCES Issues (issue_id)
);
基类表和子类表之间一对一的关系由元数据来确保,因为子类型表的外键也同样是主键,因而就必须是唯一的。这个解决方案提供了一个高效的方法来查询所有的记录,因为你仅仅查询基类的属性。一旦你找到了合适的记录,就可以通过查询对应的子类型表来获取子类型特殊化的属性。
你不需要了解在基类表中的行表示的是哪个子类型,如果仅有很少的子类型,那么可以写一个联结查询来一次性获取所有的记录,产生一个像单表继承设计里的那样稀疏结果集。当这个子类型不具有某个属性时,其值是空的。
EAV/soln/select-class.sql
SELECT
i.*, b.*, f.*
FROM
Issues AS i
LEFT OUTER JOIN Bugs AS b USING (issue_id)
LEFT OUTER JOIN FeatureRequests AS f USING (issue_id);
这也是定义一个视图的好方法。
当你经常要查询所有子类型时这个设计是最佳选择,引用这些公共列就行了。
6.5.4 半结构化数据模型
如果你有很多子类型或者你必须经常地增加新的属性支持,那么可以使用一个BLOB列来存储数据,用XML或者JSON格式——同时包含了属性的名字和值。Martin Fowler称这个模式为:序列化大对象块(Serialized LOB)。
EAV/soln/create-blob-tables.sql
CREATE TABLE Issues (
issue_id SERIAL PRIMARY KEY,
reported_by BIGINT UNSIGNED NOT NULL,
product_id BIGINT UNSIGNED,
priority VARCHAR (20),
version_resolved VARCHAR (20),
STATUS VARCHAR (20),
issue_type VARCHAR (10),
-- BUG or FEATURE attributes TEXT NOT NULL, -- all dynamic attributes
FOR the ROW FOREIGN KEY (reported_by) REFERENCES Accounts (account_id),
FOREIGN KEY (product_id) REFERENCES Products (product_id)
);
这个设计的优势之处就在于其优异的扩展性。你可以在任何时候,将新的属性添加到blob字段中。每行存储一个完整的属性集合,因此你可以有尽可能多的子类型,有多少行就可以有多少个。
相应地,该设计的缺点就是在这样的一个结构中,SQL基本上没有办法获取某个指定的属
性。你不能在一行blob字段中简单地选择一个独立的属性,并对其进行限制、聚合运算、排序等其他操作。你必须获取整个blob字段结构并通过程序去解码并且解释这些属性。
当你不能将需求和设计限制在一个有限的子类型集合中,或者当你需要绝对的灵活性以在任何时间调整属性时,这个方案就是最佳选择。
6.5.5 后处理
遗憾的是,有时你不得不使用EAV设计,比如你接手了一个项目,但不能改变它的原始设计,或者你的公司获得了一个第三方的软件,并且恰巧使用的是EAV。如果是这样的情况,请牢记在6.2节中我们所描述的那些问题,从而你可以有所准备并且计划好额外的工作来让这个设计工作良好。
综上所述,别尝试像在传统表中那样写查询语句,将实体当成单行数据读取。取而代之的是,查询和实体关联的属性并且将这些行组合在一起,就像它们存储的结构一样。
EAV/soln/post-process.sql
SELECT
issue_id,
attr_name,
attr_value
FROM
IssueAttributes
WHERE
issue_id = 1234;
查询的结果应该如下表:
| issue_id | attr_name | attr_value |
|---|---|---|
| 1234 | date_reported | 2009-06-01 |
| 1234 | description | Saving does not work |
| 1234 | priority | HIGH |
| 1234 | product | Open RoundFile |
| 1234 | reported_by | Bill |
| 1234 | severity | loss of functionality |
| 1234 | status | NEW |
这个查询对你来说写起来很容易,对数据库来说执行起来也很容易。即使当你写这个查询的时候并不知道有多少相关属性,它依旧会返回和这个事件相关的所有属性。
要使用这种格式的结果,你需要在程序中写一段代码来遍历结果集中的每一行记录,并且设置程序中对象的属性。下面有个PHP的代码范例:
EAV/soln/post-process.php
<?php
$objects = array();
$stmt = $pdo->query(
"SELECT
issue_id,
attr_name,
attr_value
FROM
IssueAttributes
WHERE
issue_id = 1234 )");
while ($row = $stmt->fetch()) {
$id = $row['issue_id'];
$field = $row['attr_name'];
$value = $row['attr_value'];
if (!array_key_exists($id, $objects)) {
$objects[$id] = new stdClass();
}
$objects[$id]->$field = $value;
}
这看上去有太多的工作要做,但这就是使用像EAV这样的一个系统套系统结构所造成的必然结果。
SQL已经提供了一个方法来明确地定义属性——在明确的列中。使用EAV设计,你让SQL使用新的方法来定义属性,因此SQL对于这种方法的支持是如此笨拙和低效也不足为奇了。
为元数据使用元数据。
下一节:的确,有些人是两面派。-- 稻草人,《绿野仙踪》