年轻人,在数学里,你们并不理解事情,你们只是去习惯。 -- 约翰•冯•诺伊曼
设计关系型数据库的过程既不靠臆断,也不神秘。你可以使用定义好的一系列规则来设计数据存储策略,从而避免冗余并防止应用程序出错,就像本书之前提到的poka-yoke方法一样。你可能听说过类似的一些概念,比如“防御设计”或者“尽早暴露错误”等。
规范化规则并不复杂,但很隐晦。开发人员通常会误解它们的原理,可能是因为他们将规则想得过于复杂了。
另一种可能性就是开发人员本身抗拒遵循规则。规则是那些具有创新精神的程序员所鄙视的东西,也是自由的对立面。
软件开发人员需要不断在简单和灵活之间进行取舍。你可以做很多重新发明轮子的工作和开发自定义的数据管理软件,或者通过遵循相关的设计,利用已有的知识和技术。
本书中我根据那些反模式的优点(或者缺点)来描述它们,来避免过于学术或者理论性。但在这个附录中,我们将看到理论也可以变得很实用。
A.1 关系是什么
“关系”这个术语并不是指表和表之间的关系。它指表自身,或者更进一步,是指表中列之间的关系。某种程度上来说,它也同时表示这两种关系。
数学家将关系定义为,两个不同数据域上的值的集合通过一定的条件得到一个所有可能组合的子集。
比如,一个包含所有棒球队名字的集合,和一个包含所有城市的集合。将每个城市和球队的组合都列出来,这个列表可以很长很长。但我们只关注这个列表的一个子集:球队和其所属城市的组合。有效的组合包括Chicago/White Sox、Chicago/Cubs或者Boston/Red Sox,但没有Miami/Red Sox。
“关系”这个词有两种用法:作为一种规则(“城市指某一支队伍所属的城市”),或者作为过滤子集的规则。在SQL中,我们可以将这个子集存储在一张有两列的表中,每一行对应一个组合。
当然,关系并不局限于只有两列,可以将任意数量的数据域,每个占一列,合并在一起组成一个关系。同时,数据域可以是32位整型数的集合,也可以是固定长度字符串的集合。
在对表进行规范化处理之前,需要确认它们的关系是合适的,它们必须满足一些条件。
A.1.1 行之间没有上下顺序
在SQL中,查询返回的结果的顺序是不定的,除非使用ORDER BY指定排序规则。当然,除了顺序,结果集中的数据总是一致的。
A.1.2 列之间没有左右顺序
无论是让Steven测试Open RoundFile这个项目的第1234号Bug,还是我们需要知道Open RoundFile的第1234号Bug是否能让Steven来验证,最终得到的查询结果应该是一样的。
这和 第19章 隐式的列 的反模式相关,那时我们使用列的顺序而不是列名。
A.1.3 重复行是不允许的
对于一个事实,进行更多的证明也不会让它变得更正确。给定一个棒球队的队名,数据就能指出它所在的城市是哪个,我们可以说城市依赖于队名。
要阻止重复记录,我们必须能区别两行数据,并且能定位指定的行。在SQL中,我们对列或者列的集合使用主键约束来确保这一点,而不管是否需要保证记录唯一性。
在其他非主键列里可能还是存在重复——波士顿有两支球队——但整体来看每一行是不重复的,因为这两支队伍的队名不同。
A.1.4 每一列只有一种类型,每一行只有一个值
关系头定义了列的名字和数据类型。每一行数据拥有的列和头中的定义必须匹配,且每一列的意义在所有行中必须一致。
第6章 实体—属性—值 的反模式有两处违反这个规则的地方。首先,EAV的表让每个实例的模型都可以自定义属性集,因此,实体的结构和任何头定义都不一样。
其次,EAV的attr_value列包含了所有实体的属性,包括Bug的报告日期、Bug的状态、Bug被指派给哪个账户等。1234这个值可能对于两个不同的属性来说都是合法的,但又完全具有不同的含义。
第7章 多态关联 中的反模式也破坏了这条规则,由于1234这个值可能会引用任意多个父表中的主键,因此无法断定不同两行中的1234是否具有相同的含义。
A.1.5 行没有隐藏组件
列中存储的是数据的值,不包含物理存储标示,诸如行ID或者对象ID。在第22章中,我们知道主键是唯一的,但并不是实际的行号。
有些数据库绕开了这条规则,提供了访问数据库内部存储细节的扩展SQL语法(比如,Oracle的ROWNUM伪列,或者PostgreSQL中的OID列)。然而,这些数据并不属于关系结构。
A.2 规范化的神话
很难再找出一个像规范化这种即使有精确定义依旧被广泛误解的主题。实际生活中,你肯定遇到过相信下面这些错误理念的开发人员。
- “规范化让数据库更慢。不规范让数据库更快。”错!的确,应用了规范化之后,查询时可能需要使用JOIN从多张分开的表中获取数据,而不规范的数据能够避免这些JOIN。比如,在 第2章 乱穿马路 中使用逗号分割的列表来获取Bug相关的产品。但如果我们同时还需要根据指定的产品获取所有相关的Bug呢?非规范化通常能简化或者提升某种类型的查询,但应用在别的查询类型上时开销就很大。非规范化也有合理使用的场景,但是在决定使用它时,应该先将数据库设计成标准的形式。第13章中的MENTOR规则也使用了非规范化。请记住,如果是为了性能而做的修改,则必须在修改前后都进行性能测量。
- “规范化也就是说将数据移到子表中,然后使用伪键引用它们。”错!你可以为了方便、性能或者存储效益等所有合理的理由而使用伪键,但别认为这和规范化有什么关系。
- “规范化就是将属性尽可能地拆分开,就像EAV设计那样。”错!通常程序员会误解“规范化”这个词,认为它把数据弄得更不可读或者不便于查询。而事实上,真正的“规范化”正好与之相反。
- “没人需要超过第三范式的规范化标准。其他的范式都太晦涩难懂,并且你永远不会用到它们的。”错!调查表明,超过20%的商业数据库的设计满足第一到第三范式,但违背第四范式。虽然这个量看上去比较小,但并不能说它就可以忽略:如果20%的程序中存在潜在的Bug会导致数据丢失,你会不想解决它吗?
A.3 什么是规范化
下面这些是规范化的目标:
- 以一种我们能够理解的方式表达这个世界中的事物;
- 减少数据的冗余存储,防止异常或者不一致的数据;
- 支持完整性约束。
请注意,提高数据的性能并不在此列表中。规范化有助于我们正确地存储数据,避免陷入麻烦。当数据库是非规范化的时候,几乎不可避免地会变成一个烂摊子,我们需要编写更多的代码来清理不一致的或者重复的数据,最终我们会因为错误数据而不得不延期项目以及投入更多的成本。如果将所有这些场景考虑进去,就更容易看出规范化所带来的效率提升。
当一张表满足规范化的规则时,我们便称这张表符合范式。有五种传统的范式,描述了依次递进的规范化等级。每种范式消除了一种特定类型的冗余或者异常情况。通常来说,如果一张表的设计满足某一层级的范式,那这张表一定满足前面所有层级的范式。研究人员还定义了这五种传统范式之外的另外三种范式。范式的渐进级别如图A-1所示。
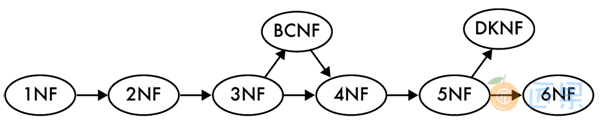
A.3.1 第一范式
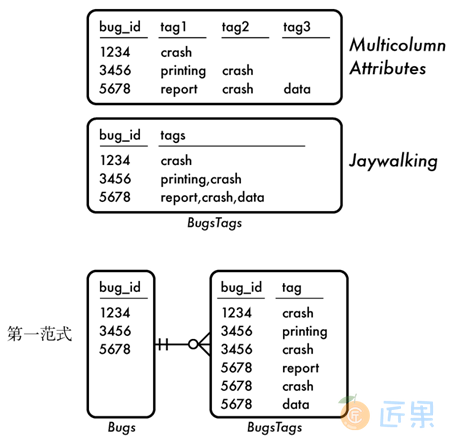
第一范式的最根本要求是,该表必须是一个关系。如果它不符合A.1节中所描述的关系准则,那么这张表就不符合第一范式和后续的范式。
接下来的要求是这张表必须没有重复组合。请记住,关系中的每一行,都是从多个集合的每一个集合中选一个值形成的一种组合。重复的组合说明这一行可能有多个来自于同一个集合的值。
我们曾经见过两个创建了重复组合的反模式。
从图A-2中可以看到这两个反模式中的重复组合。满足第一范式的更合理的设计应该是创建一个单独的表,tag占用单独的一列,并且通过每行存储一个标签来支持多个标签的存储。
A.3.2 第二范式
除了复合主键之外,第二范式和第一范式是一样的。在之前的标签例子中,我们保持跟踪哪些用户给Bug打上了特定标签,我们还要关注是谁第一个创造了某一个标签。
Normalization/2NF-anti.sql
CREATE TABLE BugsTags (
bug_id BIGINT NOT NULL,
tag VARCHAR (20) NOT NULL,
tagger BIGINT NOT NULL,
coiner BIGINT NOT NULL,
PRIMARY KEY (bug_id, tag),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (tagger) REFERENCES Accounts (account_id),
FOREIGN KEY (coiner) REFERENCES Accounts (account_id)
);
在图A-3中,可以看到创造者标识的存储是冗余的。1这意味着修改了某一个tag(如crash)的创造者的标识,如果没有同步所有相同标签的行,则会导致数据异常。
1 此图使用用户名字而非ID号来标识用户。
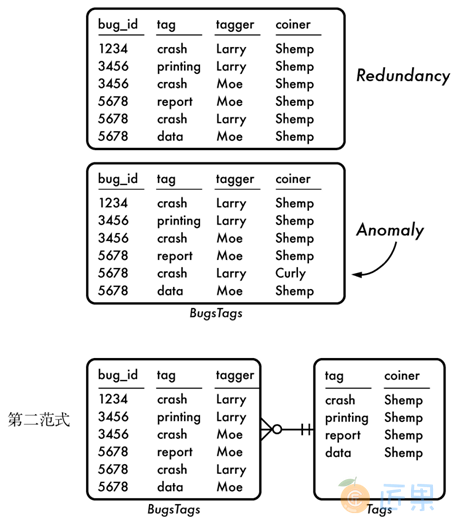
为了满足第二范式,我们应该对于每个tag只存储一次它的创造者。也就是说,我们不得不额外定义一张表Tags,以tag作为主键,这样每一个tag就只有一行了。接着,我们就可以将tag的创造者从BugsTags表里移到这张表中,从而防止了异常发生。
Normalization/2NF-normal.sql
CREATE TABLE Tags (
tag VARCHAR (20) PRIMARY KEY,
coiner BIGINT NOT NULL,
FOREIGN KEY (coiner) REFERENCES Accounts (account_id)
);
CREATE TABLE BugsTags (
bug_id BIGINT NOT NULL,
tag VARCHAR (20) NOT NULL,
tagger BIGINT NOT NULL,
PRIMARY KEY (bug_id, tag),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (tag) REFERENCES Tags (tag),
FOREIGN KEY (tagger) REFERENCES Accounts (account_id)
);
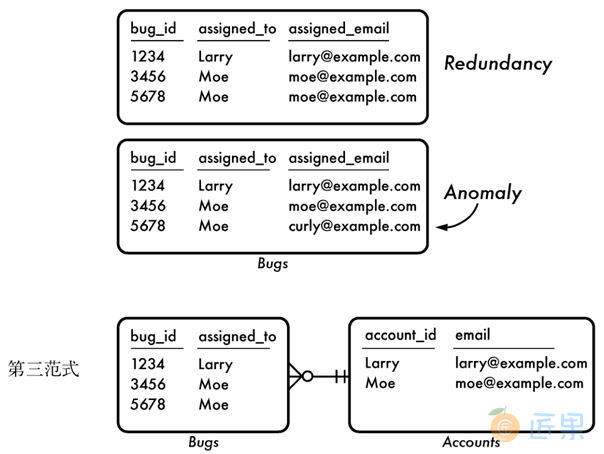
A.3.3 第三范式
在Bugs这张表中,可能需要记录处理Bug的工程师的E-mail。
Normalization/3NF-anti.sql
CREATE TABLE Bugs (
bug_id SERIAL PRIMARY KEY -- . . .
assigned_to BIGINT,
assigned_email VARCHAR (100),
FOREIGN KEY (assigned_to) REFERENCES Accounts (account_id)
);
然而,E-mail是这个被分配任务的工程师账号的一个属性,并不是Bug的属性。以这种形式存储E-mail就是冗余的,并且我们需要面对之前不满足第二范式时产生的那种风险。
第二范式例子中的那个犯规的列至少还部分和复合主键相关,而在第三范式的这个例子中,E-mail这一列和主键就没有一点关联了。
要解决这一问题,我们需要将E-mail地址放到Accounts表中。图A-4显示了如何拆分Bugs表。由于在Accounts表中的E-mail是直接和主键关联而没有冗余的,因而这才是E-mail的合适位置。
A.3.4 博伊斯—科德范式
比第三范式稍微严格一点的范式版本称为博伊斯—科德范式。这两个范式之间的不同之处在于,在第三范式中,所有的非关键字列都必须直接依赖于这张表中的关键字列,而在博伊斯—科德范式中,所有关键字列也必须遵循这一规则,这一点在一张表有多种列的集合可作为表的关键字时才有效。
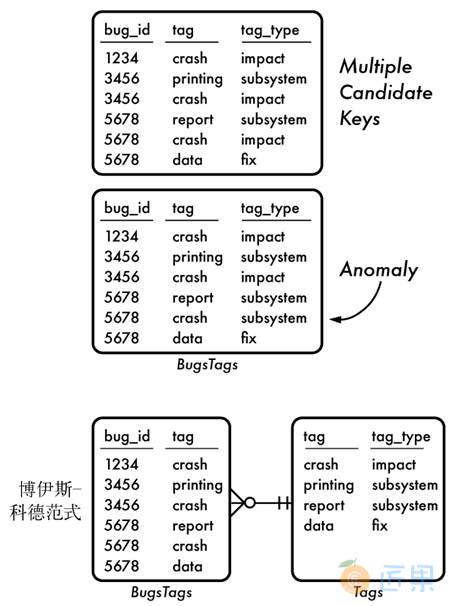
比如,我们有三种Tag类型:描述Bug所造成影响的tag,描述Bug影响子系统的tag,以及Bug修复状态的tag。每一个Bug对于每一种Tag类型只能有一个tag。可能的键组合包括bug_id加上tag,或者bug_id加上tag_type。这两种组合都应该足够定位每一个独立的行。
在图A-5中,可以看到一个满足第三范式但是不满足博伊斯—科德范式的表,以及如何修改才能让它满足博伊斯—科德范式。
A.3.5 第四范式
现在,我们需要修改数据库,以支持多个用户报告同一个Bug,并分配给多个开发工程师,然后由多个质量工程师验证。我们知道多对多的关系需要一张额外的表:
Normalization/4NF-anti.sql
CREATE TABLE BugsAccounts (
bug_id BIGINT NOT NULL,
reported_by BIGINT,
assigned_to BIGINT,
verified_by BIGINT,
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (reported_by) REFERENCES Accounts (account_id),
FOREIGN KEY (assigned_to) REFERENCES Accounts (account_id),
FOREIGN KEY (verified_by) REFERENCES Accounts (account_id)
);
我们不能单独使用bug_id作为主键。每个Bug需要多行数据来实现各个字段都支持多个账号的目的。也不能将前两列或者前三列作为复合主键,因为这样,最后一列依旧不支持多个值。因此,主键必须是由所有四列组成。然而,assigned_to和verified_by需要可以为空,因为Bug在被指派和验证之前是可以报告的。而标准情况下,所有的主键列都有一个非空的约束。
另一问题就是当某一列的账号数小于其他列时,就会造成数据冗余。图A-6显示了这种冗余。
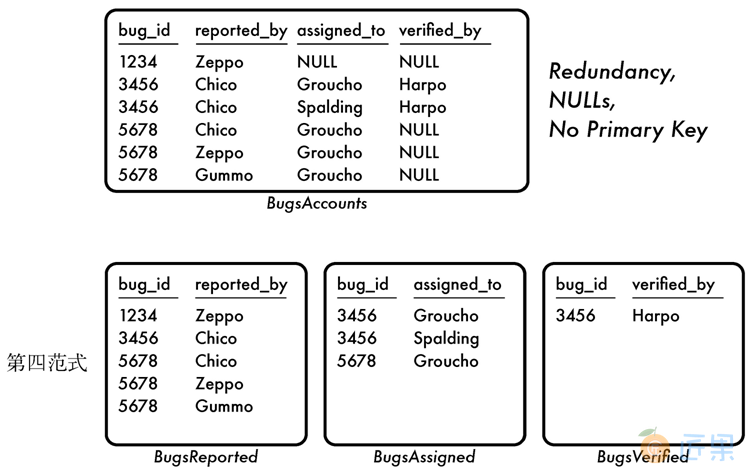
上面提出的这些问题都是由于创建了一张做了双倍或者三倍工作的交叉表。当尝试使用一张交叉表描述多个多对多关系时,就会违背第四范式。
图A-6展示了我们可以拆分这张表来解决问题。我们应该为每一种多对多关系使用一张单独的交叉表,这就解决了冗余和数量不匹配的问题。
Normalization/4NF-normal.sql
CREATE TABLE BugsReported (
bug_id BIGINT NOT NULL,
reported_by BIGINT NOT NULL,
PRIMARY KEY (bug_id, reported_by),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (reported_by) REFERENCES Accounts (account_id)
);
CREATE TABLE BugsAssigned (
bug_id BIGINT NOT NULL,
assigned_to BIGINT NOT NULL,
PRIMARY KEY (bug_id, assigned_to),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (assigned_to) REFERENCES Accounts (account_id)
);
CREATE TABLE BugsVerified (
bug_id BIGINT NOT NULL,
verified_by BIGINT NOT NULL,
PRIMARY KEY (bug_id, verified_by),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (verified_by) REFERENCES Accounts (account_id)
);
A.3.6 第五范式
任何满足博伊斯—科德范式并且没有复合主键的表将同时满足第五范式。我们可以通过下面的这个例子来更好地理解第五范式。
有些工程师只为几个产品服务。我们应该将数据库设计成让我们了解谁在为哪些产品服务,以及在修复哪些Bug,并且最小化数据的冗余。首先我们会想到在BugsAssigned表中增加一列来展示是哪个工程师在处理:
Normalization/5NF-anti.sql
CREATE TABLE BugsAssigned (
bug_id BIGINT NOT NULL,
assigned_to BIGINT NOT NULL,
product_id BIGINT NOT NULL,
PRIMARY KEY (bug_id, assigned_to),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (assigned_to) REFERENCES Accounts (account_id),
FOREIGN KEY (product_id) REFERENCES Products (product_id)
);
但这不足以告诉我们这个工程师可以被指派为哪些产品服务,它只表明了这个工程师当前被指派去服务哪些产品,同时,这么做也造成了重复的存储。这是由于想在一张表中存储多种独立的多对多关系而产生的,就像我们在第四范式中所看到的问题一样。图A-7描述了这种冗余。2
2 图中使用了用户名字而不是ID。

我们的解决方案是将每个关系都分别放到不同的表中:
Normalization/5NF-normal.sql
CREATE TABLE BugsAssigned (
bug_id BIGINT NOT NULL,
assigned_to BIGINT NOT NULL,
PRIMARY KEY (bug_id, assigned_to),
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (assigned_to) REFERENCES Accounts (account_id),
FOREIGN KEY (product_id) REFERENCES Products (product_id)
);
CREATE TABLE EngineerProducts (
account_id BIGINT NOT NULL,
product_id BIGINT NOT NULL,
PRIMARY KEY (account_id, product_id),
FOREIGN KEY (account_id) REFERENCES Accounts (account_id),
FOREIGN KEY (product_id) REFERENCES Products (product_id)
);
现在我们可以记录某个工程师能为哪个产品服务,而不依赖于这个工程师是否正在为那个产品的Bug努力。
A.3.7 更多的范式
DK范式(Domain-Key normal form)认为表上的每个约束都是这张表的数据域约束和关键字约束的逻辑结果。DK范式涵盖了第三、四、五范式和博伊斯—科德范式。
比如说,一个状态为NEW或者DUPLICATE的Bug应该是没有任何工作量的,因此应该没有工作时间记录,也不需要在verified_by列中指派质量工程师。可能的实现方法是使用一个触发器或者一个CHECK约束。这些都是建在表的非关键字列上的约束,因而它们并不符合DK范式的标准。
第六范式旨在消除所有的联结依赖,它通常用来支持属性的变更历史。比如,我们可能想要在一张子表中记录下Bugs.status随着时间推移产生的变化:何时发生的变更,谁做的变更,以及其他可能的细节。
可以想象,如果让Bugs这张表满足第六范式,几乎每一列都需要附带一个历史记录表。这会导致表的数量过多。第六范式对于大多数程序来说都是没有必要的,但一些数据仓库技术里会使用到第六范式。3
3 比如,Anchor Modeling就是用了第六范式(http://www.anchormodeling.com)。
A.4 常识
规范化规则并不深奥或者复杂。它们只是减少冗余和提高数据一致性的惯用技术方法。
你可以使用这份关于关系和范式的简单参考资料,来帮助自己在未来的项目中更好地设计数据库。