常见的 PHP、Java 的 FreeMarker 等开发的网站,动态内容是由服务器端渲染写入 HTML 并传输到浏览器进行展示。页面间的相互跳转是通过 标签进行切换的,这样的网站百度能够很轻松地爬取,并沿着 标签爬取到子级页面。
而近几年流行的 Vue、React、Angular 之类的框架所开发出的应用都是 SPA 应用(单页Web 应用 (single-page application 简称为 SPA)),这种应用仅有一个HTML页面,所有的资源(HTML、JavaScript、CSS等)都在该页面初始化时加载。界面的切换是则是利用 JavaScript 动态的变换HTML 内容实现。由于避免了页面和资源的反复加载,SPA 应用能够提供流畅的用户体验。随之而来的缺点也是显而易见的,由于渲染工作放到的前端且只有一个 HTML 页面,无论网站有多少个页面,百度蜘蛛也只能爬到首页(Google 支持 SPA 应用)。这就令开发者们不得不针对性地做许多 SEO 方面的工作。
- SSR 服务器渲染,利用 NuxtJs 对 Vue 开发的网站进行服务器端渲染。适用于网站规模比较大或动态内容较多的情况。缺点是学习成本高,老项目需要大量的重构,还需要额外的服务器资源及开发成本;
- 网站静态化,通过 Web 服务器实时将网站转化为静态的 HTML 实现对搜索引擎的支持。适用于网站规模较小且动态内容较少的情况。
- 预渲染:无需使用 Web 服务器实时编译 HTML,而是使用预渲染方式,在构建时 (build time) 简单地生成针对特定路由的静态 HTML 文件。优点是设置预渲染更简单,并可以将你的前端作为一个完全静态的站点。
- Phantomjs 针对爬虫做处理,即正常的访问还是走 SPA,爬虫访问时,通过 Phantomjs 在服务器端实时渲染成 HTML。优点是不破坏程序结构,用户体验,成本相对更低。实测发现 Phantomjs 时常发生渲染不出来的情况。于是换了更优的解决方案 Prerender.io。Prerender.io 与 Phantomjs 的原理相同,通过对网站预渲染,可以将网站页面渲染之后再返回给网络爬虫,间接完成网页的解析。Prerender 相较于其他的解决方案,配置相对要简单一些,无须对现有代码做改动。流程入下:
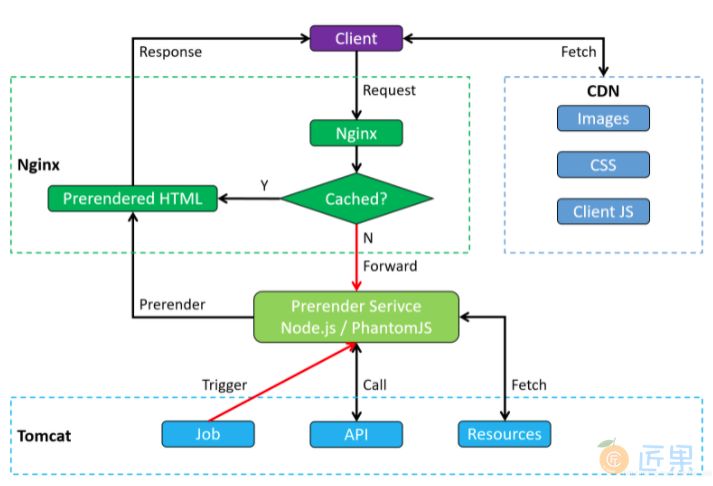
要利用 Prerender.io 做网站的预渲染,需要 NodeJS、Nginx、Chrome 的支持。具体安装流程和操作方法如下:
安装
1. NodeJS
1、在官网下载和自己系统匹配的文件:
2、解压后建立软链接
- ln -s /app/software/nodejs/bin/npm /usr/local/bin/
- ln -s /app/software/nodejs/bin/node /usr/local/bin/
- 在Linux命令行node -v 命令会显示nodejs版本。
2. Nginx
安装方法网上查,这里仅讲一下仅对 Prerender.io 的配置。如下:
server {
location / {
# proxy_set_header Host $host:$proxy_port;
# proxy_set_header X-Real-IP $remote_addr;
# proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
try_files $uri @prerender;
}
location @prerender {
# 将 YOUR_TOKEN替换为你的个人token
proxy_set_header X-Prerender-Token YOUR_TOKEN;
set $prerender 0;
# 注意:这里将蜘蛛的访问转发至 NodeJS
if ($http_user_agent ~* "Baiduspider|Baiduspider-mobile|Baiduspider-news|Baiduspider-favo|Baiduspider-cpro|360Spider|Sogou Pic Spider|Sosospider|googlebot|bingbot|yandex|baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator") {
set $prerender 1;
}
if ($args ~ "_escaped_fragment_") {
set $prerender 1;
}
if ($http_user_agent ~ "Prerender") {
set $prerender 0;
}
if ($uri ~* "\.(js|css|xml|less|png|jpg|jpeg|gif|pdf|doc|txt|ico|rss|zip|mp3|rar|exe|wmv|doc|avi|ppt|mpg|mpeg|tif|wav|mov|psd|ai|xls|mp4|m4a|swf|dat|dmg|iso|flv|m4v|torrent|ttf|woff|svg|eot)") {
set $prerender 0;
}
#resolve using Google's DNS server to force DNS resolution and prevent caching of IPs
resolver 8.8.8.8;
# 爬虫访问,则转发至 NodeJS
if ($prerender = 1) {
# 后续将service.prerender.io替换为自己的prerender服务,如127.0.0.1:3000
set $prerender "NodeJS服务器IP:3000";
rewrite .* /$scheme://$host$request_uri? break;
proxy_pass http://$prerender;
}
# 用户访问,转发至业务服务
if ($prerender = 0) {
#rewrite .* index.html break;
proxy_pass http://业务服务器IP:80;
}
}
}
Prerender.io
- 首先注册登录 Prerender.io 获得个人token,该网站不一定打的开,没有 token 也可以正常使用;
- 到 GitHub 下载安装包,
git clone https://github.com/prerender/prerender.git并安装。如下:
cd /usr/prerender
# Phantomjs 官方的下载地址会超时,此处重新指定其下载地址为淘宝镜像
export PHANTOMJS_CDNURL=https://npm.taobao.org/mirrors/phantomjs
npm install
Chrome
cd /ect/yum.repos.d/
touch google-chrome.repo
vi google-chrome.repo
在 google-chrome.repo 中写入如下内容:
[google-chrome]
name=google-chrome
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch
enabled=1
gpgcheck=1
gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
保存后,运行:
yum -y install google-chrome-stable --nogpgcheck
Chrome 的安装路径为:/opt/google/chrome
运行
Chrome
默认情况下,root用户不能直接运行Chrome,所以须要新建一个用户如other来运行。
su other // 切换用户
cd /usr/local/web/prerender
nohup node ./server.js &
如果开启了防火墙,需要将3000端口加入防火墙。
firewall-cmd —zone=public —add-port=3000/tcp —permanent
# 重启防火墙
firewall-cmd —reload
NodeJS
修改 NodeJS 的 server.js 文件如下:
#!/usr/bin/env node
var prerender = require('./lib');
var server = prerender({
pageDoneCheckInterval: 100,
pageLoadTimeout: 10000,
waitAfterLastRequest: 500
});
server.use(prerender.sendPrerenderHeader());
server.use(prerender.blockResources());
server.use(prerender.removeScriptTags());
server.use(prerender.httpHeaders());
server.start();
- pageDoneCheckInterval:prerender 检查页面请求是否完成的定时器时间,默认是500ms,即每500ms检查未完成的请求数量是否为零,我将其修改为100ms,提高其检查的频率。检查页面是否完成加载之间的毫秒数;
- pageLoadTimeout: 页面加载时间,包括了AJAX请求等时间;
- waitAfterLastRequest: 最后一个请求完成之后等待的时间,默认是500ms,主要是请求完成之后,页面更新渲染需要时间,立即返回的话,可能请求的数据来不及渲染,我将时间修改为200ms。
- followRedirects:默认 false。如果遇到重定向,Chrome是否在第一个请求上重定向。通常,出于SEO目的,您不希望遵循重定向。相反,您希望Prerender服务器将重定向返回给爬虫,以便它们可以更新自己的索引。除非你知道自己在做什么,否则不要将其设置为true。您还可以设置FOLLOW_REDIRECTS 的环境变量,而无需传入followRedirects参数;
- server.use(prerender.blockResources()):无需等待图片资源;
测试
# 如果本地安装了 prerender 环境
curl http://localhost:3000/render?url=https://www.jiangguo.net/
# 如果没有本地环境,则模拟百度访问
curl --user-agent "Baiduspider" http://www.jiangguo.net
由于 Prerender 是在爬虫访问时实时渲染的,服务器性能较弱的话可能需要3秒甚至更张的时间才能返回结果,这将导致百度认为网站不稳定而不再爬取,下一章我们将重点解决该问题。