基于二进制日志的复制、基于 GTID 的复制、半同步复制、高可用架构 MMM 和 MHA
一、日志格式
1.1 二进制日志格式
MySQL 二进制日志是进行主从复制的基础,它记录了所有对 MySQL 数据库的修改事件,包括增删改查和表结构修改。当前 MySQL 一共支持三种二进制日志格式,可以通过 binlog-format 参数来进行控制,其可选值如下:
- STATEMENT :段格式。是 MySQL 最早支持的二进制日志格式。其记录的是实际执行修改的 SQL 语句,因此在进行批量修改时其所需要记录的数据量比较小,但对于 UUID() 或者其他依赖上下文的执行语句,可能会在主备上产生不一样的结果。
- ROW :行格式,是 MySQL 5.7 版本之后默认的二进制日志格式。其记录的是修改前后的数据,因此在批量修改时其需要记录的数据量比较大,但其安全性比较高,不会导致主备出现不一致的情况。同时因为 ROW 格式是在从库上直接应用更改后的数据,其还能减少锁的使用。
- MIXED :是以上两种日志的混合方式,默认采用段格式进行记录,当段格式不适用时 (如 UUID() ),则默认采用 ROW 格式。
通常在主备之间网络情况良好的时,可以优先考虑使用 ROW 格式,此时数据一致性最高,其次是 MIXED 格式。在设置 ROW 格式时,还有一个非常重要的参数 binlog_row_image :
1.2 binlog_row_image
binlog_row_image 有以下三个可选值:
- full :默认值,记录行在修改前后所有列的值。
- minimal :只记录修改涉及列的值。
- noblob :与 full 类似,但如果 BLOB 或 TEXT 列没有修改,则不对其进行记录。
binlog-format 和 binlog_row_image 的默认值可能在不同版本存在差异,可以使用以下命令进行查看。通常情况下,为了减少在主备复制中需要传输的数据量,可以将 binlog_row_image 的值设置为 minimal 或 noblob。
show variables like 'binlog_format';
show variables like 'binlog_row_image';
二、基于二进制日志的复制
2.1 复制原理
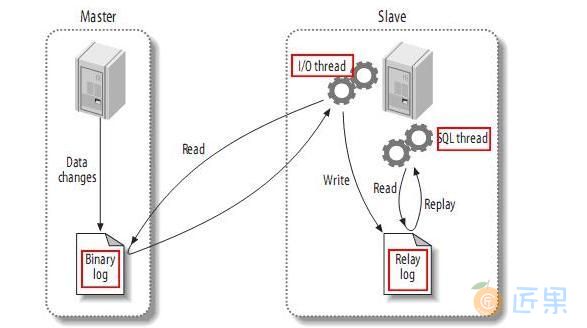
MySQL 的复制原理如下图所示:
- 主库首先将变更写入到自己的二进制日志中;
- 备库会启动一个 IO 线程,然后主动去主库节点上获取变更日志,并写入到自己的中继日志中。
- 之后从中继日志中读取变更事件,在从库上执行变更。
- 当备库与主库数据状态一致,备库的 IO 线程就会进入睡眠。当主库再次发生变更时,其会向备库发出信号,唤醒 IO 线程并再次进行工作。
如果没有进行任何配置,主库在将变更写入到二进制日志后,就会返回对客户端的响应,因此默认情况下的复制是完全异步进行的,主备之间可能会短暂存在数据不一致的情况。
2.2 配置步骤
首先主节点需要开启二进制日志,并且在同一个复制环境下,主备节点的 server-id 需要不一样:
[mysqld]
server-id = 226
# 开启二进制日志
log-bin=mysql-bin
在备份节点配置中继日志:
[mysqld]
server-id = 227
# 配置中继日志
relay_log = mysql-relay-bin
# 为了保证数据的一致性,从节点应该设置为只读
read_only = 1
# 以下两个配置代表是否开启二进制日志,如果该从节点还作为其他备库的主节点,则开启,否则不用配置
log-bin = mysql-bin
# 是否将中继节点收到的复制事件写到自己的二进制日志中
log_slave_updates = 1
登录主节点 MySQL 服务,创建用于进行复制账号,并为其授予权限:
CREATE USER 'repl'@'192.168.0.%' IDENTIFIED WITH mysql_native_password BY '123456';
GRANT REPLICATION SLAVE on *.* TO 'repl'@'192.168.0.%' ;
查看主节点二进制日志的状态:
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 887 | | | |
+------------------+----------+--------------+------------------+-------------------+
基于日志和偏移量,建立复制链路:
CHANGE MASTER TO MASTER_HOST='192.168.0.226',\
MASTER_USER='repl', \
MASTER_PASSWORD='123456',\
MASTER_LOG_FILE='mysql-bin.000001',\
MASTER_LOG_POS=887;
开始复制:
START SLAVE;
查看从节点复制状态,主要参数有 Slave_IO_Running 和 Slave_SQL_Running,其状态都为 Yes 表示用于复制的 IO 进程已经开启。Seconds_Behind_Master 参数表示从节点复制的延迟量。此时可以在主库上进行任意更改,并在备库上查看情况。
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.226
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 887
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 322
Relay_Master_Log_File: mysql-bin.000001
# Slave_IO_Running: Yes
# Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 887
Relay_Log_Space: 530
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
# Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 226
# Master_UUID: e1148574-bdd0-11e9-8873-0800273acbfd
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set (0.00 sec)
2.3 优缺点
基于二进制日志的复制是 MySQL 最早使用的复制技术,因此 MySQL 对其的支持比较完善,对执行修改的 SQL 语句几乎没有任何限制。其主要的缺点是在一主多从的高可用复制架构中,如果主库发生宕机,此时想要自动通过从库的日志和偏移量来确定新的主库比较困难。
三、基于 GTID 的复制
2.1 GTID 简介
MySQL 5.6 版本之后提供了一个新的复制模式:基于 GTID 的复制。GTID 全称为 Global Transaction ID,即全局事务 ID。它由每个服务节点的唯一标识和其上的事务 ID 共同组成,格式为: server_uuid : transaction_id 。通过 GTID ,可以保证在主库上的每一个事务都能在备库上得到执行,不会存在任何疏漏。
2.2 配置步骤
主从服务器均增加以下 GTID 的配置:
gtid-mode = ON
# 防止执行不受支持的语句,下文会有说明
enforce-gtid-consistency = ON
如果配置过上面的基于二进制日志的复制,还需要在从服务器上执行以下命令,关闭原有复制链路:
STOP SLAVE IO_THREAD FOR CHANNEL '';
建立新的基于 GTID 复制链路,指定 MASTER_AUTO_POSITION = 1 表示由程序来自动确认开始同步的 GTID 的位置:
CHANGE MASTER TO MASTER_HOST='192.168.0.226',\
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_AUTO_POSITION=1;
开始复制:
START SLAVE;
在主节点上执行任意修改操作,并查看从节点状态,关键的输出如下:Retrieved_Gtid_Set 代表从主节点上接收到的两个事务,Executed_Gtid_Set 表示这两个事务已经在从库上得到执行。
mysql> SHOW SLAVE STATUS\G
....
Master_UUID : e1148574-bdd0-11e9-8873-0800273acbfd
Retrieved_Gtid_Set : e1148574-bdd0-11e9-8873-0800273acbfd:1-2
Executed_Gtid_Set : e1148574-bdd0-11e9-8873-0800273acbfd:1-2
.....
2.3 优缺点
GTID 复制的优点在于程序可以自动确认开始复制的 GTID 点。但其仍然存在以下限制:
- 不支持 CREATE TABLE ... SELECT 语句。 因为在 ROW 格式下,该语句将会被记录为具有不同 GTID 的两个事务,此时从服务器将无法正确处理。
- 事务,过程,函数和触发器内部的 CREATE TEMPORARY TABLE 和 DROP TEMPORARY TABLE 语句均不受支持。
为防止执行不受支持的语句,建议配置和上文配置一样,开启 enforce-gtid-consistency 属性, 开启后在主库上执行以上不受支持的语句都将抛出异常并提示。
四、半同步复制
在上面我们介绍过,不论是基于二进制日志的复制还是基于 GTID 的复制,其本质上都是异步复制,假设从节点还没有获取到二进制日志信息时主节点就宕机了,那么就会存在数据不一致的问题。想要解决这个问题可以通过配置半同步复制来实现:进行半同步复制时,主节点会等待至少一个从节点获取到二进制日志后才将事务的执行结果返回给客户端。具体配置步骤如下:
1. 安装插件
MySQL 从 5.5 之后开始以插件的形式支持半同步复制,所以先需要先进行插件的安装,命令如下:
-- 主节点上执行
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
-- 从节点上执行
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
如果你的复制是基于高可用架构的,即从节点可能会在主节点宕机后成为新的主节点,而原主节点可能在失败恢复后成为从节点,那么为了保证半同步复制仍然有效,此时可以在主从节点上都安装主从插件。安装后使用以下命令查看是否安装成功:
mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME LIKE '%semi%';
+----------------------+---------------+
| PLUGIN_NAME | PLUGIN_STATUS |
+----------------------+---------------+
| rpl_semi_sync_master | ACTIVE |
| rpl_semi_sync_slave | ACTIVE |
+----------------------+---------------+
2. 配置半同步复制
半同步复制可以基于日志复制或 GTID 复制开启,只需要在其原有配置上增加以下配置:
# 主节点上增加如下配置:
plugin-load=rpl_semi_sync_master=semisync_master.so
rpl_semi_sync_master_enabled=1
# 从节点上增加如下配置:
plugin-load=rpl_semi_sync_slave=semisync_slave.so
rpl_semi_sync_slave_enabled=1
# 和上面提到的一样,如果是高可用架构下,则主从节点都可以增加主从配置:
plugin-load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl-semi-sync-master-enabled = 1
rpl-semi-sync-slave-enabled = 1
3. 启动复制
按照二进制日志或 GTID 的方式正常启动复制即可,此时可以使用如下命令查看半同步日志是否正在执行:
# 主节点
mysql> SHOW STATUS LIKE 'Rpl_semi_sync_master_status';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| Rpl_semi_sync_master_status | ON |
+-----------------------------+-------+
# 从节点
mysql> SHOW STATUS LIKE 'Rpl_semi_sync_slave_status';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
值为 ON 代表半同步复制配置成功。
4. 可选配置
半同步日志还有以下两个可选配置:一个是 rpl_semi_sync_master_wait_for_slave_count,它表示主节点需要至少等待几个从节点复制完成,默认值为 1,因为等待过多从节点可能会导致长时间的延迟,所以通常使用默认值即可。另一个常用参数是 rpl_semi_sync_master_wait_point ,它主要是用于控制等待的时间点,它有以下两个可选值:
- AFTER_SYNC (默认值):主服务器将每个事务写入其二进制日志,并将二进制日志同步到磁盘后开始进行等待。在收到从节点的确认后,才将事务提交给存储引擎并将结果返回给客户端。
- AFTER_COMMIT :主服务器将每个事务写入其二进制日志并同步到磁盘,然后将事务提交到存储引擎,提交后再进行等待。在收到从节点的确认后,才将结果返回给客户端。
第二种方式是 MySQL 5.7.2 之前默认方式,但这种方式会导致数据的丢失,所以在 5.7.2 版本后就引入了第一种方式作为默认方式,它可以实现无损复制 (lossless replication),数据基本无丢失,因此 rpl_semi_sync_master_wait_point 参数通常也不用进行修改,采用默认值即可。想要查看当前版本该参数的值,可以使用如下命令:
mysql> SHOW VARIABLES LIKE 'rpl_semi_sync_master_wait_point';
+---------------------------------+------------+
| Variable_name | Value |
+---------------------------------+------------+
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
+---------------------------------+------------+
虽然半同步复制能够最大程度的避免数据的丢失,但是因为网络通讯会导致额外的等待时间的开销,所以尽量在低延迟的网络环境下使用,如处于同一机房的主机之间。
五、高可用架构
不论是主主复制结构,还是一主多从复制结构,单存依靠复制只能解决数据可靠性的问题,并不能解决系统高可用的问题,想要保证高可用,系统必须能够自动进行故障转移,即在主库宕机时,主动将其它备库升级为主库。常用的有以下两种解决方案:
5.1 MMM
MMM (Master-Master replication manager for MySQL) 是由 Perl 语言开发的一套支持双主故障切换以及双主日常管理的第三方软件。它包含两类角色:writer 和 reader,分别对应读写节点和只读节点。使用 MMM 管理的双主节点在同一时间上只允许一个进行写入操作,当 writer 节点出现宕机(假设是 Master1),程序会自动移除该节点上的读写 VIP,然后切换到 Master2 ,并设置 Master2 的 read_only = 0,即关闭只读限制,同时将所有 Slave 节点重新指向 Master2。
除了管理双主节点,MMM 也负责管理所有 Slave节点,在出现宕机、复制延迟或复制错误,MMM 会移除该节点的 VIP,直至节点恢复正常。MMM 高可用的架构示例图如下:
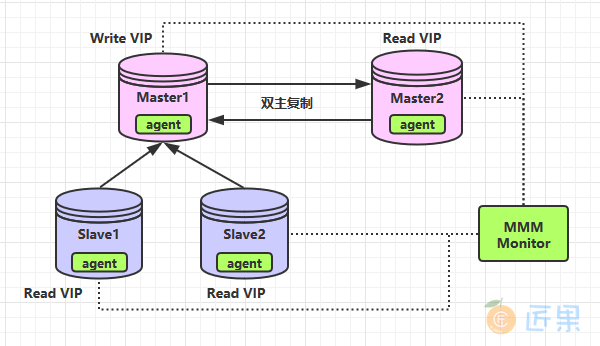
MMM 架构的缺点在于虽然其能实现自动切换,但却不会主动补齐丢失的数据,所以会存在数据不一致性的风险。另外 MMM 的发布时间比较早,所以其也不支持 MySQL 最新的基于 GTID 的复制,如果你使用的是基于 GTID 的复制,则只能采用 MHA。### 5.2 MHA
MHA (Master High Availability) 是由 Perl 实现的一款高可用程序,相对于 MMM ,它能尽量避免数据不一致的问题。它监控的是一主多从的复制架构,架构如下图所示:

在 Master 节点宕机后,其处理流程如下:1. 尝试从宕机 Master 中保存二进制日志;
- 找到含有最新中继日志的 Slave;
- 把最新中继日志应用到其他实例,保证各实例数据一致;
- 应用从 Master 保存的二进制日志事件;
- 提升一个 Slave 为 Master ;
- 其他 Slave 向该新 Master 同步。
按照以上的处理流程,MHA 能够最大程序的避免数据不一致的问题。但如果 Master 所在的服务器也宕机了,那么过程的第一步就会失败。在 MySQL 5.5 后,可以开启半同步复制后来避免这个问题,从而可以保证数据的一致性和几乎无丢失。当然 MHA 集群也存在一下一些缺点:
- 集群中所有节点之间需要开启 SSH 服务,所以会存在一定的安全影响。
- 没有实现 Slave 的高可用。
- 自带的脚本不足,例如虚拟 IP 的配置需要自己通过命令或者其他第三方软件来实现。
- 需要手动清理中继日志。
以上就是 MMM 和 MHA 架构的简单介绍,关于其具体搭建步骤,可以参考以下两篇博客: MySQL集群搭建(3)-MMM高可用架构 和 MySQL集群搭建(5)-MHA高可用架构。