不知道你有没有注意到,这一节的标题是"EBLK日志分析平台",而上一节的标题中是"ELK日志分析平台"。是的,你没有看错,这也不是笔误。
在ELK平台中,Logstash负责收集微服务的各种Log文件,发送给Elasticsearch。
当微服务数量少、副本数也不多的时候,Logstash是可以胜任的。随着微服务数量不断增多,副本数不断增长,Logstash的负载会越来越高,极易造成单点故障。
此外,在我们的微服务架构下,各个微服务进程是运行在Kubernetes集群上的,它们的日志文件可能分散在各个物理机上。如何让单一的Logstash收集这些遍布各处的日志文件,也是一个难题。
一个简单的想法就是启用边车模式,即每个微服务启动时,同时伴随部署一个Logstash,这样就可以解决单点故障和收集的问题。
想法是好的,但Logstash本身的结构较为复杂,同时具有监听文件、网络、批处理等各种复杂功能,此外Logstash需要JVM运行环境,内存占用较大。
为了更加轻量级级的收集日志,Elasticsearch推出了Beat,我们以边车模式伴随微服务进行部署。关于Beat与Logstash的对比,可以参考这篇文章。
Beat负责收集日志,并将日志发送给Logstash。这样看起来还是没有解决Logstash的单点故障?
是的,但经过Beat转发后,我们实际上可以配置多个Logstah结点从而解决掉单点故障。
此外,Beat可以缓存日志,当Logstash挂掉后,会自动重试。Logstash恢复后,可以继续处理日志的发送。加上B这一层后,整EBLK的架构如下所示:
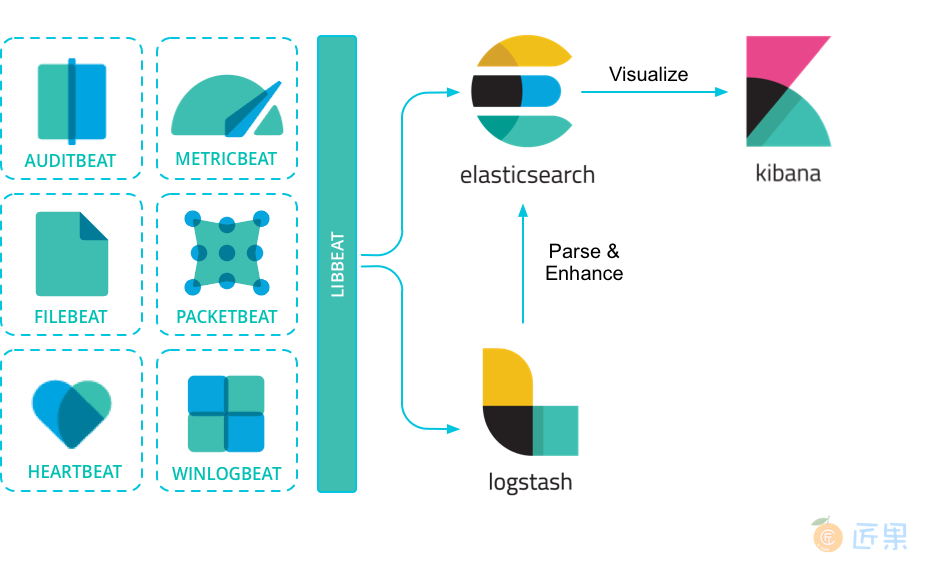
在本小节的前半部分,我们将在一个受限环境中,使用Beat收集日志,并发送给Logstash。后半部分,将讨论如何在Kubernetes中应用便车模式,让Beat伴随微服务一同启动。
使用Beat收集日志
Beats是一系列日志收集工具的统称,官方推出了多种Beat,如:Filebeat, Metricbeat, Packetbeat, Winlogbeat等等,详细可以参见官方介绍。
在我们的场景下,需要解析微服务输出的日志文件,直接用Filebeat即可。
首先来看一下FileBeat的配置:
apiVersion: v1
data:
filebeat.yml: |
filebeat.inputs:
- type: log
enabled: true
multiline.pattern: '^2'
multiline.negate: true
multiline.match: after
name: filebeat-test
paths:
- /usr/share/filebeat/*.log
output.logstash:
hosts: ["logstash-0.ls:5555"]
kind: ConfigMap
metadata:
name: filebeat-configmap
上述配置包含2个部分:
- 输入监听/user/share/filebeat/下后缀为log的文件,这里只是限定环境下的测试,并非线上微服务的日志,支持多行自动合并为同一个事件(主要是异常时调用堆栈信息)。
- 输出到logstash, logstash-0.ls:5555
然后我们看一下FileBeat的服务定义:
apiVersion: v1
kind: Service
metadata:
name: ls
spec:
ports:
- name: p
port: 5000
selector:
app: filebeat
clusterIP: None
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: filebeat
spec:
selector:
matchLabels:
app: filebeat
serviceName: "ls"
replicas: 1
template:
metadata:
labels:
app: filebeat
spec:
hostname: filebeat
containers:
- name: filebeat-ct
image: docker.elastic.co/beats/filebeat:6.3.2
env:
- name: "ES_JAVA_OPTS"
value: "-Xms384m -Xmx384m"
- name: "XPACK_MONITORING_ENABLED"
value: "false"
- name: "XPACK_MONITORING_ELASTICSEARCH_URL"
value: "http://elasticsearch-0.es:9200"
volumeMounts:
- name: filebeat-configmap
mountPath: /usr/share/filebeat/filebeat.yml
subPath: filebeat.yml
volumes:
- name: filebeat-configmap
configMap:
name: filebeat-configmap
如上所示,配置基本与之前的Logstash相同,并且加载了刚配置好的filebeat.yml。
Logstash汇总日志
对应地,logstash也需要做对应的调整:
apiVersion: v1
data:
logstash.conf: |
input {
beats {
port => 5555
}
}
filter {
grok {
match => {"message" => "(?m)^(?<TIMESTAMP>%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}) \[%{LOGLEVEL:LEVEL}\] \[(?<THREAD>.*?)\] \[(?<LOGGER>.*?)\] \[tr=(?<TRACE_ID>.*?)\]\s+(?<MSG>.*)" }
}
}
output {
elasticsearch {
hosts => [ 'elasticsearch-0.es' ]
user => 'elastic'
password => ''
}
}
kind: ConfigMap
metadata:
name: logstash-configmap
如上所示,我们修改了logstash的配置:
- input是beat格式,端口5555,与上面filebeat的配置对应
- filter对输入的beat事件进行解析。这里使用了grok插件,具体的语法可以参考官方grok插件介绍
- output输出到Elasticsearch,这里没有变化
我们重启Logstash和FileBeat后,尝试向FileBeat的Docker中写入几行日志,稍等几秒,打开Kibana,可以发现,日志已经可以检索到了。
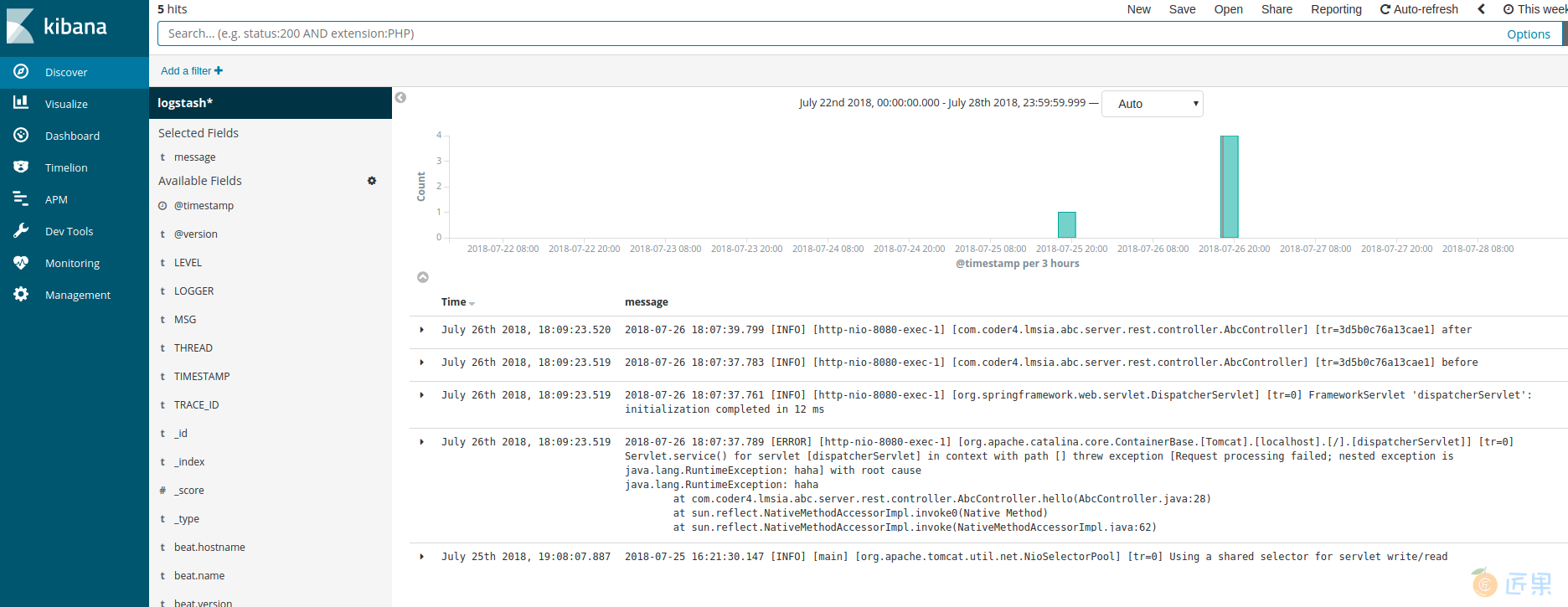
将FileBeat与Spring Boot进行整合
前面已经提到,微服务数量、副本数众多、遍布在集群的各个物理机上,日志收集、汇总起来非常麻烦,所以一般来说,需要使用边车模式,即一个微服务伴随一个日志收集器(FileBeat)。
上述模式的实现,有两个技术选择:
- 使用Kubernetes的Pod多容器模式
- 手动将FileBeat打包进微服务的镜像内。
方案二比较传统,也易于理解,可以参考这篇文章
而方案一,则是利用了Kubernetes的原生支持特性。
Kubernets中的最小操作单位是Pod,Pod中可以启动多个Docker容器,且同他们之间共享同样的磁盘、端口。
关于微服务的服务定义、FileBeat定义,我们前面已经分别介绍过了,所需要做的,就是将他们“粘贴”到同一个Pod里面。
这里,我不再赘述具体描述,而是作为一个思考题留给你来实现。如果实现起来有困难,可以参考Multi-Container Pods in Kubernetes。