数据建模中的关键挑战是平衡应用程序的需求、数据库引擎的性能以及数据检索模式。 在设计数据模型时,始终需要考虑数据的应用程序使用情况(即数据的查询,更新和处理)以及数据本身的固有结构。
灵活的 Schema
在关系型数据库中,必须在插入数据之前确定并声明表的结构。而 MongoDB 的 collection 默认情况下不需要其文档具有相同的架构。也就是说:同一个 collection 中的 document 不需要具有相同的 field 集,并且 field 的数据类型可以在集合中的不同文档之间有所不同。要更改 collection 中的 document 结构,例如添加新 field,删除现有 field 或将 field 值更改为新类型,只需要将文档更新为新结构即可。这种灵活性有助于将 document 映射到实体或对象。每个 document 都可以匹配所表示实体的数据字段,即使该文档与集合中的其他文档有很大的不同。但是,实际上,集合中的文档具有相似的结构,并且您可以在更新和插入操作期间对 collection 强制执行 document 校验规则。
Document 结构
嵌入式数据模型
嵌入式 document 通过将相关数据存储在单个 document 结构中来捕获数据之间的关系。 MongoDB document 可以将 document 结构嵌入到另一个 document 中的字段或数组中。这些非规范化的数据模型允许应用程序在单个数据库操作中检索和操纵相关数据。

对于 MongoDB 中的很多场景,非规范化数据模型都是最佳的。
嵌入式 document 有大小限制:必须小于 16 MB。
如果是较大的二进制数据,可以考虑 GridFS (opens new window)。
引用式数据模型
引用通过包含从一个 document 到另一个 document 的链接或引用来存储数据之间的关系。 应用程序可以解析这些引用以访问相关数据。 广义上讲,这些是规范化的数据模型。
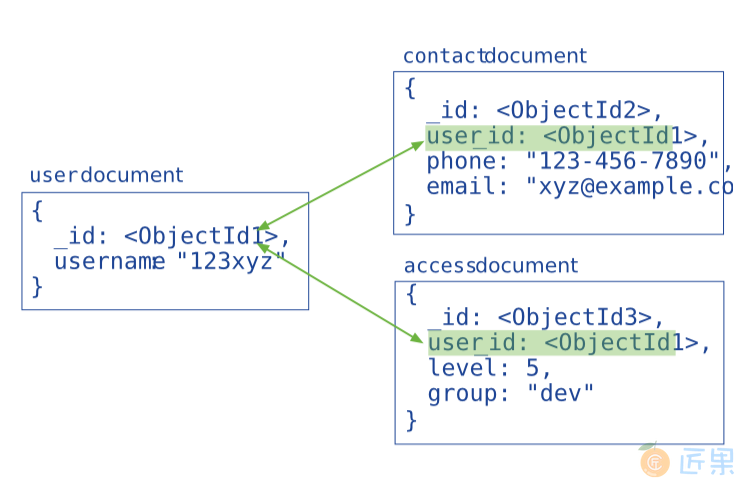
通常,在以下场景使用引用式的数据模型:
- 嵌入时会导致数据重复,但无法提供足够的读取性能优势,无法胜过重复的含义。
- 代表更复杂的多对多关系。
- 为大规模分层数据集建模。
为了 join collection,MongoDB 支持聚合 stage:
$lookup(opens new window)(MongoDB 3.2 开始支持)$graphLookup(opens new window)(MongoDB 3.4 开始支持)
MongoDB 还提供了引用来支持跨集合 join 数据:
原子写操作
单 document 的原子性
在 MongoDB 中,针对单个 document 的写操作是原子性的,即使该 document 中嵌入了多个子 document。 具有嵌入数据的非规范化数据模型将所有相关数据合并在一个 document 中,而不是在多个 document 和 collection 中进行规范化。 该数据模型有助于原子操作。 当单个写入操作(例如 db.collection.updateMany() (opens new window))修改多个 document 时,每个 document 的独立修改是原子的,但整个操作不是原子的。
多 document 事务
对于需要对多个 document(在单个或多个集合中)进行读写原子性的情况,MongoDB 支持多 document 事务。
- 在版本 4.0 中,MongoDB 在副本集上支持多 document 事务。
- 在版本 4.2 中,MongoDB 引入了分布式事务,它增加了对分片群集上多 document 事务的支持,并合并了对副本集上多 document 事务的现有支持。
在大多数情况下,多 document 事务会比单 document 的写入产生更高的性能消耗,并且多 document 事务的可用性不能替代高效的结构设计。 在许多情况下,非规范化数据模型(嵌入式 document 和数组)仍是最佳选择。 也就是说,合理的数据建模,将最大程度地减少对多 document 事务的需求。
数据使用和性能
在设计数据模型时,请考虑应用程序将如何使用您的数据库。 例如,如果您的应用程序仅使用最近插入的 document,请考虑使用上限集合。 或者,如果您的应用程序主要是对 collection 的读取操作,则添加索引以提高性能。