本章的最后将描述读取与写入堆元组的方式。
1.4.1 写入堆元组
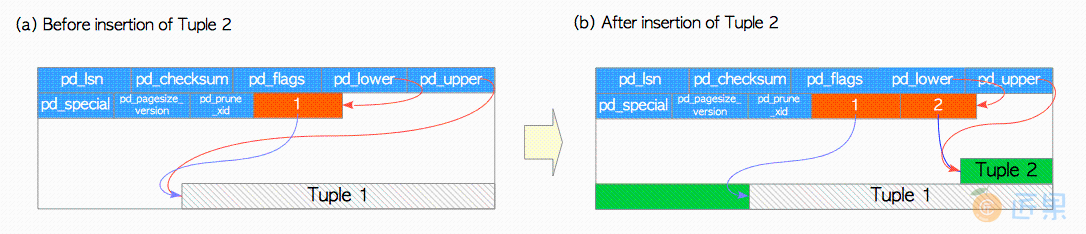
让我们假设有一个表,仅由一个页面组成,且该页面只包含一个堆元组。 此页面的pd_lower指向第一个行指针,而该行指针和pd_upper都指向第一个堆元组。 如图1.5(a)所示。
当第二个元组被插入时,它会被放在第一个元组之后。第二个行指针被插入到第一个行指针的后面,并指向第二个元组。 pd_lower更改为指向第二个行指针,pd_upper更改为指向第二个堆元组,如图1.5(b)。 页面内的首部数据(例如pd_lsn,pg_checksum,pg_flag)也会被改写为适当的值,细节在 5.3 元组的增删改 和 第九章 预写式日志——WAL 中描述。
1.4.2 读取堆元组
这里简述两种典型的访问方式:顺序扫描与B树索引扫描:
- 顺序扫描 —— 通过扫描每一页中的行指针,依序读取所有页面中的所有元组,如图1.6(a)。
- B树索引扫描 —— 索引文件包含着索引元组,索引元组由一个键值对组成,键为被索引的列值,值为目标堆元组的TID。进行索引查询时,首先使用键进行查找,如果找到了对应的索引元组,PostgreSQL就会根据相应值中的TID来读取对应的堆元组 (使用B树索引找到索引元组的方法请参考相关资料,这一部分属于数据库系统的通用知识,限于篇幅这里不再详细展开)。例如在图1.6(b)中,所获索引元组中TID的值为(区块号 = 7,偏移号 = 2), 这意味着目标堆元组是表中第7页的第2个元组,因而PostgreSQL可以直接读取所需的堆元组,而避免对页面做不必要的扫描。
图 1.6 顺序扫描和索引扫描
PostgreSQL还支持TID扫描 ,位图扫描(Bitmap-Scan) 和仅索引扫描(Index-Only-Scan) 。
TID扫描是一种通过使用所需元组的TID直接访问元组的方法。 例如要在表中找到第0个页面中的第1个元组,可以执行以下查询:
sampledb=# SELECT ctid, data FROM sampletbl WHERE ctid = '(0,1)'; ctid | data -------+----------- (0,1) | AAAAAAAAA (1 row) sampledb=# EXPLAIN SELECT ctid, data FROM sampletbl WHERE ctid = '(0,1)'; QUERY PLAN ---------------------------------------------------------- Tid Scan on sampletbl (cost=0.00..1.11 rows=1 width=38) TID Cond: (ctid = '(0,1)'::tid)仅索引扫描将在 第七章 堆内元组与仅索引扫描 中详细介绍。