下一个需要解决的问题是如何在保持不可变好处的同时更新倒排索引。答案是,使用多个索引。
不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
Elasticsearch底层依赖的Lucene,引入了per-segment search的概念。一个段(segment)是有完整功能的倒排索引,但是现在Lucene中的索引指的是段的集合,再加上提交点(commit point,包括所有段的文件),如图1 所示。新的文档,在被写入磁盘的段之前,首先写入内存区的索引缓存,如图2、图3 所示。
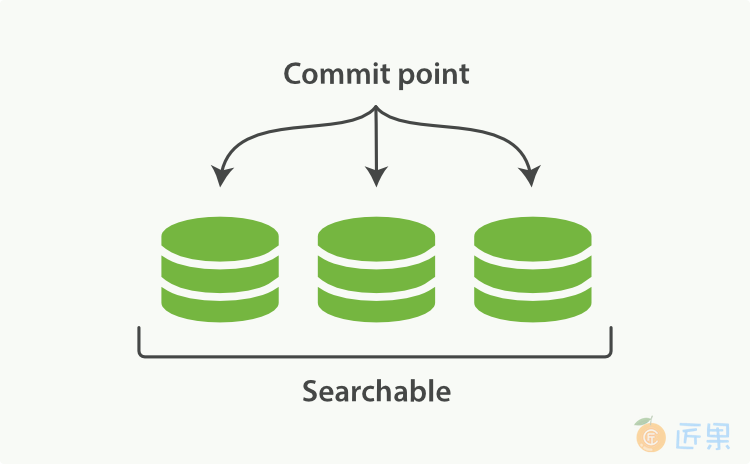
索引vs分片
为了避免混淆,需要说明,Lucene索引是Elasticsearch中的分片,Elasticsearch中的索引是分片的集合。当Elasticsearch搜索索引时,它发送查询请求给该索引下的所有分片,然后过滤这些结果,聚合成全局的结果。
一个per-segment search如下工作:
- 新的文档首先写入内存区的索引缓存。
- 不时,这些buffer被提交:
- 一个新的段——额外的倒排索引——写入磁盘。
- 新的提交点写入磁盘,包括新段的名称。
- 磁盘是fsync’ed(文件同步)——所有写操作等待文件系统缓存同步到磁盘,确保它们可以被物理写入。
- 新段被打开,它包含的文档可以被检索
- 内存的缓存被清除,等待接受新的文档。
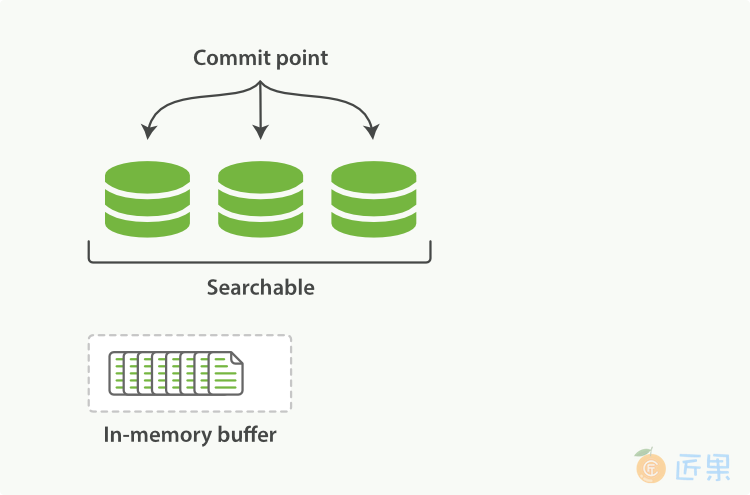

当一个请求被接受,所有段依次查询。所有段上的Term统计信息被聚合,确保每个term和文档的相关性被正确计算。通过这种方式,新的文档以较小的代价加入索引。
删除和更新
段是不可变的,所以文档既不能从旧的段中移除,旧的段也不能更新以反映文档最新的版本。相反,每一个提交点包括一个.del文件,包含了段上已经被删除的文档。当一个文档被删除,它实际上只是在.del文件中被标记为删除,依然可以匹配查询,但是最终返回之前会被从结果中删除。文档的更新操作是类似的:当一个文档被更新,旧版本的文档被标记为删除,新版本的文档在新的段中索引。也许该文档的不同版本都会匹配一个查询,但是更老版本会从结果中删除。在合并段这节,我们会展示删除的文件是如何从文件系统中清除的。