服务的熔断及降级是系统鲁棒性的关键之一,这与我们常听说的服务雪崩有着紧密的关系。
🔆 鲁棒性(Robustness)意为健壮、强壮,在计算中指的是系统的健壮性,用于表示容忍可能影响系统功能的扰动的能力。详见此处
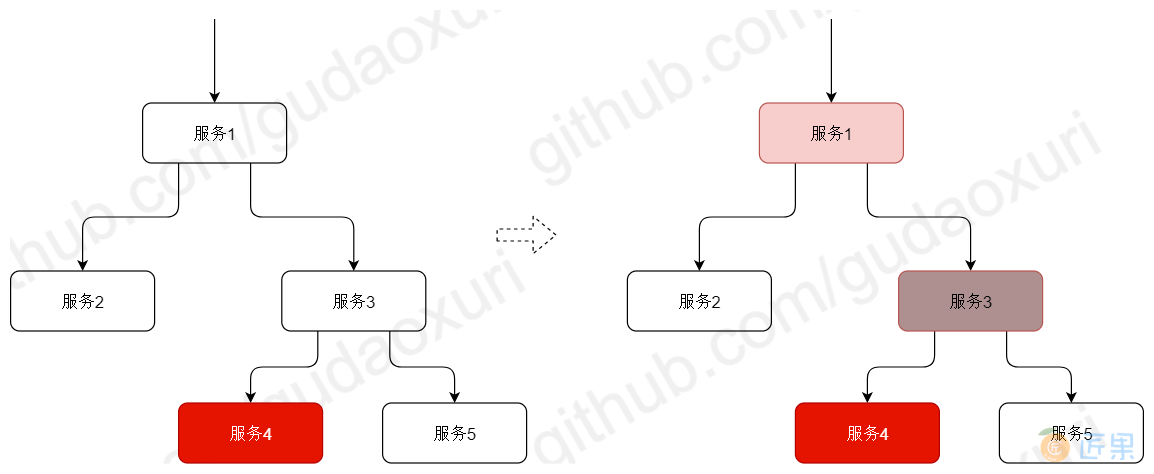
上图是服务雪崩的示例,假设我们的系统由5个服务组成,服务1调用服务2、3,服务3调用服务4、5,但由于某些原因(到达性能极限、未知bug、网络分区等)服务4访问很慢,这时如果没有服务的熔断与降级那么调用者服务3会因为服务4异常而积累过多请求导致产生大量等待的线程(BIO模型),进而服务3也会引发访问慢或中止服务的问题,对其调用服务1也会重复服务3的问题,如此一来,由服务4本身的问题而引发依赖服务的整个链路都出问题,这就是典型的服务雪崩效应。
雪崩效应之所以这么被重视是因为它极容易在被人们忽视的情况下发生,对微服务而言,服务实例成百上千,我们很难一个个服务地检查以保证每个服务的质量,并且很多情况下只有在达到一定压力问题才会暴露,常规的代码Reivew或是针对单个服务的压力测试未必可以发现问题,再则这些依赖服务未必都是我们自己的服务,如果说我们自己服务尚有一定的排查优化方法的话那么对三方服务依赖而言那几乎只能是凭经验了,只要我的依赖服务中存在一处不起眼的bug,或是过少的连接池配置,抑或是网络波动都有可能引发雪崩。
怎么有效地避免呢?我们可以尝试这样解决:
设置每个请求的超时时间以避免服务请求一直等待下去。还是以上图为例,如果服务4僵死了,那么发往服务4的请求必定会超时,假定超时时间1s,那么原本可能在100ms内完成的请求都要等到1s,在请求量大的情况下,服务3还是会出现请求堆积,逐级向上进而导致雪崩。
所以我们还要做这样的约束:设置每个请求的超时时间,超时N次就不再请求。再套用上图的例子我们发现这的确起到立竿见影的效果,可有效地防止雪崩,这也是服务熔断的核心实现之一。
但这也存在一定的问题,在很多情况下服务异常是瞬时的,比如网络波动、中间件异常(多可自我恢复)、并发量陡增等,我们的策略是超时N次不再请求,这就导致了服务恢复后系统也会处于不用状态。
更好的做法是可以自动探测服务是否正常以进行熔断和恢复请求。比如我们的规则可以修改成:请求超时N次后在X时间不再请求实现熔断,X时间后恢复M%的请求,如果M%的请求都成功(未超时)则恢复正常关闭熔断,否则再熔断Y时间,依此循环。
这样看上去好多了,但这种粗放式的熔断服务会导致这些请求返回错误,更优雅的方式是实现服务降级,即在依赖服务异常后可以有替代的逻辑以提供备用,比如某一流程很重要,在依赖的服务异常后我们尝试让调用方临时查询依赖服务的缓存数据,缓存数据的实时性可能比较低,但不失为一种临时的解决方案。
当然我们还可以做得更多,服务异常很多情况下是并发量陡增导致,那么我们可以引入限流或排队的方案(见后续章节),使用限流直接挡掉一批请求,或是使用排队机制让多过的请求等待。
当我们把这样因素及实现都思考之后就形成了一个比较理想的熔断处理方案了,其核心是通过熔断实现服务保护,它体现在对请求做限流或排队以防止并发超过服务预设指标,通过熔断及智能的恢复防止系统雪崩,引入可选的降级流程提升服务的可用性。
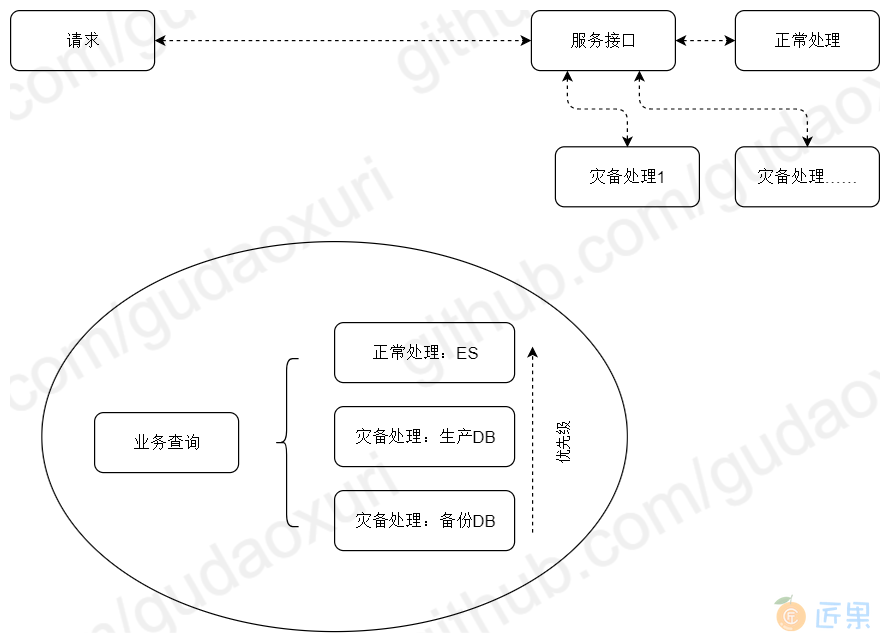
下面举个例子进一步说明熔断与降级,对于数据查询场景我们可以会引入ES以提升查询的性能降低数据库的压力,这是正常的逻辑,但如果ES查询异常时要确保服务可用就需要走降级灾备方案,灾备方案1是使用资源有限定的只读账号查询生产数据库,如果达到限定值为不影响其它业务只能进入灾备方案2,灾备方案2查询的是备份库,备份库在性能、数据实时性上都有损失,但起码可以让服务尽可能地可用(当然要视具体场景而言)。
熔断器要求可以根据服务的情况自动升降级。一个标准的熔断器一般都包含三个状态:
- Closed:熔断器关闭状态,即服务正常
- Open:熔断器打开状态,直接返回错误,不再发起请求(没有网络开销)
- Half-Open:半熔断状态,介于关闭和打开之间,此状态下会发送少量请求给对应的服务,如果调用成功且达到一定比例则恢复服务关闭熔断器,反之回到熔断器打开状态
Hystrix是目前最成熟的熔断器之一,它是一个类库,方便与我们的系统继承,实现了上述功能外还提供监控、报警及可视化操作能力,目前成熟的JVM微服务框架都有其集成方案。
⚠ Hystrix已处于维护期,不再添加新功能,推荐使用更轻量的resilience4j。
下一节:接上文书,服务各接口要考虑熔断与降级,这更偏向于技术手段及具体的接口或服务,我们的系统由众多的服务组成,在系统层面上也必须考虑整体的可降级设计,而这更偏向于业务设计。