- 客户端将文件写入本地磁盘的N#x4E34;时文件中
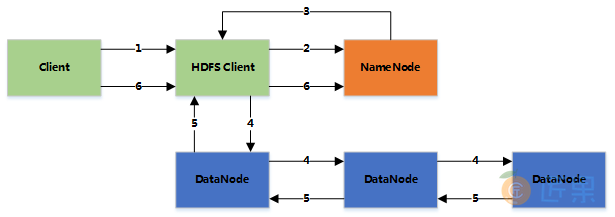
- 当临时文件大小达到一个block大小时,HDFS client通知NameNode,申请写入文件
- NameNode在HDFS的文件系统中创建一个文件,并把该block id和要写入的DataNode的列表返回给客户端
- 客户端收到这些信息后,将临时文件写入DataNodes
- 客户端将文件内容写入第一个DataNode(一般以4kb为单位进行传输)
- 第一个DataNode接收后,将数据写入本地磁盘,同时也传输给第二个DataNode
- 依此类推到最后一个DataNode,数据在DataNode之间是通过pipeline的方式进行复制的
- 后面的DataNode接收完数据后,都会发送一个确认给前一个DataNode,最终第一个DataNode返回确认给客户端
- 当客户端接收到整个block的确认后,会向NameNode发送一个最终的确认信息
- 如果写入某个DataNode失败,数据会继续写入其他的DataNode。然后NameNode会找另外一个好的DataNode继续复制,以保证冗余性
- 每个block都会有一个校验码,并存放到独立的文件中,以便读的时候来验证其完整性
- 文件写完后(客户端关闭),NameNode提交文件(这时文件才可见,֘#x5982;果提交前,NameNode垮掉,那文件也就丢失了。fsync:只保证数据的信息写到NameNode上,但并不保证数据已经被写到DataNode中)
Rack aware(机架感知)
通过配置文件指定机架名和DNS的对应关系
假设复制参数是3,在写入文件时,会在本地的机架保存一份数据,然后在另外一个机架内保存两份数据(同机架内的传输速度快,从而提高性能)
整个HDFS的集群,最好是负载平衡的,这样才能尽量利用集群的优势