事实上我们的电脑只认识0与1,记录的数据也是只能记录0与1而已,所以电脑常用的数据是二进制的。 但是我们人类常用的数值运算是十进制,文字方面则有非常多的语言,台湾常用的语言就有英文、中文(又分正体与简体中文)、日文等。 那么电脑如何记录与显示这些数值/文字呢?就得要通过一系列的转换才可以啦!下面我们就来谈谈数值与文字的编码系统啰!
0.3.1 数字系统
早期的电脑使用的是利用通电与否的特性的真空管,如果通电就是1,没有通电就是0, 后来沿用至今,我们称这种只有0/1的环境为二进制制,英文称为binary的哩。所谓的十进制指的是逢十进一位, 因此在个位数归为零而十位数写成1。所以所谓的二进制,就是逢二就前进一位的意思。
那二进制怎么用呢?我们先以十进制来解释好了。如果以十进制来说,3456的意义为:3456 = 3x10^3^ + 4x10^2^ + 5x10^1^ + 6x10^0^
特别注意:“任何数值的零次方为1”所以100的结果就是1啰。 同样的,将这个原理带入二进制的环境中,我们来解释一下1101010的数值转为十进制的话,结果如下:1101010=1x2^6^ + 1x2^5^ + 0x2^4^ + 1x2^3^ + 0x2^2^ + 1x2^1^ + 0x2^0^ = 64 + 32 + 0x16 + 8 + 0x4 + 2 + 0x1 = 106
这样你了解二进制的意义了吗?二进制是电脑基础中的基础喔!了解了二进制后,八进位、十六进制就依此类推啦! 那么知道二进制转成十进制后,那如果有十进制数值转为二进制的环境时,该如何计算? 刚刚是乘法,现在则是除法就对了!我们同样的使用十进制的106转成二进制来测试一下好了:
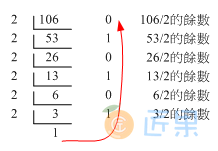
最后的写法就如同上面的红色箭头,由最后的数字向上写,因此可得到1101010的数字啰! 这些数字的转换系统是非常重要的,因为电脑的加减乘除都是使用这些机制来处理的! 有兴趣的朋友可以再参考一下其他计算计概论的书籍中,关于1的补数/2的补数等运算方式喔!
0.3.2 文字编码系统
既然电脑都只有记录0/1而已,甚至记录的数据都是使用Byte/bit等单位来记录的,那么文字该如何记录啊? 事实上文字文件也是被记录为0与1而已,而这个文件的内容要被取出来查阅时,必须要经过一个编码系统的处理才行。 所谓的“编码系统”可以想成是一个“字码对照表”,他的概念有点像下面的图示:
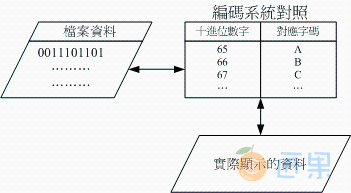
当我们要写入文件的文字数据时,该文字数据会由编码对照表将该文字转成数字后,再存入文件当中。 同样的,当我们要将文件内容的数据读出时,也会经过编码对照表将该数字转成对应的文字后,再显示到屏幕上。 现在你知道为何浏览器上面如果编码写错时,会出现乱码了吗?这是因为编码对照表写错, 导致对照的文字产生误差之故啦!
常用的英文编码表为ASCII系统,这个编码系统中, 每个符号(英文、数字或符号等)都会占用1Bytes的记录, 因此总共会有28=256种变化。至于中文字当中的编码系统早期最常用的就是big5这个编码表了。 每个中文字会占用2Bytes,理论上最多可以有216=65536,亦即最多可达6万多个中文字。 但是因为big5编码系统并非将所有的位都拿来运用成为对照,所以并非可达这么多的中文字码的。 目前big5仅定义了一万三千多个中文字,很多中文利用big5是无法成功显示的~所以才会有造字程序说。
big5码的中文字编码对于某些数据库系统来说是很有问题的,某些字码例如“许、盖、功”等字, 由于这几个字的内部编码会被误判为单/双引号,在写入还不成问题,在读出数据的对照表时, 常常就会变成乱码。不只中文字,其他非英语系国家也常常会有这样的问题出现啊!
为了解决这个问题,由国际组织ISO/IEC跳出来制订了所谓的Unicode编码系统, 我们常常称呼的UTF8或万国码的编码就是这个咚咚。因为这个编码系统打破了所有国家的不同编码, 因此目前网际网络社会大多朝向这个编码系统在走,所以各位亲爱的朋友啊,记得将你的编码系统修订一下喔!
下一节:鸟哥在上课时常常会开玩笑的问:“我们知道没有插电的电脑是一堆废铁,那么插了电的电脑是什么?” 答案是:“一堆会电人的废铁”!这是因为没有软件的运行,电脑的功能就无从发挥之故。 就好像没有了灵魂的躯体也不过就是行尸走肉,重点在于软件/灵魂啰!所以下面咱们就得要了解一下“软件”是什么。
一般来说,目前的电脑系统将软件分为两大类,一个是系统软件,一个是应用程序。但鸟哥认为我们还是得要了解一下什么是程序, 尤其是机器程序,了解了之后再来探讨一下为什么现今的电脑系统需要“操作系统”这玩意儿呢!