线上调试
线上调试的典型场景譬如:
- 程序在稳定运行了,可是实现的功能点了没反应。
- 为了修复 Bug 而上线的新版本,上线后发现 Bug 依然在,却想不通哪里有问题?
- 想到可能出现问题的地方,却发现那里没打日志,没法在运行中看到问题,只能加了日志输出重新打包——部署——上线
- 程序功能正常了,可是为啥响应时间这么慢,在哪里出现了问题?
- 程序不但稳定运行,而且功能完美,但跑了几天或者几周过后,发现响应速度变慢了,是不是内存泄漏了?
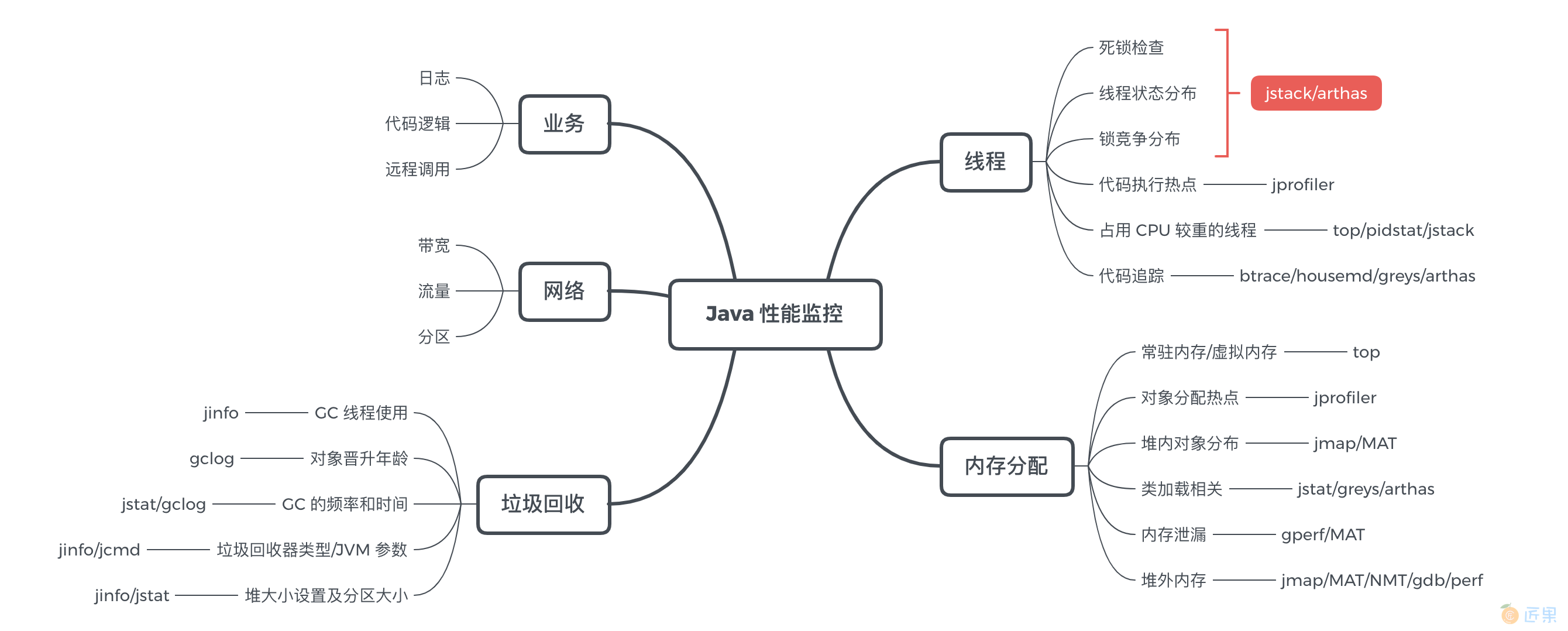
如果瓶颈点在应用层和系统层均呈现出多变量分布,建议此时使用 JProfiler 等工具对应用进行 Profiling,获取应用的综合性能信息(注:Profiling 指的是在应用运行时,通过事件(Event-based)、统计抽样(Sampling Statistical)或植入附加指令(Byte-Code instrumentation)等方法,收集应用运行时的信息,来研究应用行为的动态分析方法)。譬如,可以对 CPU 进行抽样统计,结合各种符号表信息,得到一段时间内应用内的代码热点。
调试工具
常见内置工具的使用
# 查看堆内对象的分布 Top 50(定位内存泄漏)
$ jmap –histo:live $pid | sort-n -r -k2 | head-n 50
# 按线程状态统计线程数(加强版)
$ jstack $pid | grep java.lang.Thread.State:|sort|uniq -c | awk '{sum+=$1; split($0,a,":");gsub(/^[ \t]+|[ \t]+$/, "", a[2]);printf "%s: %s\n", a[2], $1}; END {printf "TOTAL: %s",sum}';
# 查看最消耗 CPU 的 Top10 线程机器堆栈信息
$ show-busy-java-threads
jstack
jstack 命令主要用于调试 Java 程序运行过程中的线程堆栈信息,可以用于检测死锁,进程耗用 CPU 过高报警问题的排查。
$ jstack
Usage:
jstack [-l] <pid>
jstack -F [-m] [-l] <pid>
Options:
-F 强制dump线程堆栈信息. 用于进程hung住,jstack <pid>命令没有响应的情况
-m 同时打印java和本地(native)线程栈信息,m是mixed mode的简写
-l 打印锁的额外信息Copy to clipboardErrorCopied
典型用法
jstack 的典型用法如下:
- qmq 是部署在 Tomcat 中的应用名
$ ps -ef | grep qmq | grep -v grepCopy to clipboardErrorCopied - 拿到进程号,例如上面对应的是 3192
- 第二步找出该进程内最耗费 CPU 的线程,可以使用 ps -Lfp pid 或者 ps -mp pid -o THREAD, tid, time 或者 top -Hp pid。例如用第三个 top -Hp 3192:
Tasks: 123 total, 0 running, 123 sleeping, 0 stopped, 0 zombie Cpu(s): 0.3%us, 0.4%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 3922688k total, 3272588k used, 650100k free, 432768k buffers Swap: 4194296k total, 0k used, 4194296k free, 596488k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3494 tomcat 20 0 4905m 1.1g 11m S 0.3 28.4 0:51.91 java 3551 tomcat 20 0 4905m 1.1g 11m S 0.3 28.4 4:46.32 java 3588 tomcat 20 0 4905m 1.1g 11m S 0.3 28.4 0:07.35 java 3192 tomcat 20 0 4905m 1.1g 11m S 0.0 28.4 0:00.00 java 3194 tomcat 20 0 4905m 1.1g 11m S 0.0 28.4 0:00.82 javaCopy to clipboardErrorCopied - TIME 列就是各个 Java 线程耗费的 CPU 时间,CPU 时间最长的是线程 ID 为 3551 的线程,用
printf "%x\n" 3551得到 ddf - sudo -u Tomcat jstack 3192 | grep ddf
"New I/O worker #30" daemon prio=10 tid=0x00007f44fd525800 nid=0xde4 runnable [0x00007f4530ddf000] "DubboResponseTimeoutScanTimer" daemon prio=10 tid=0x00007f44fca88000 nid=0xddf waiting on condition [0x00007f45322e5000]Copy to clipboardErrorCopied
线程信息详解
jstack 命令会打印出所有的线程,包括用户自己启动的线程和 jvm 后台线程,我们主要关注的是用户线程,如:
$ jstack 15525
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.65-b01 mixed mode):
"elasticsearch[Native][merge][T#1]" #98 daemon prio=5 os_prio=0 tid=0x00007f031c009000 nid=0x4129 waiting on condition [0x00007f02f61ee000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000eea589f0> (a org.elasticsearch.common.util.concurrent.EsExecutors$ExecutorScalingQueue)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
at java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
at java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
....Copy to clipboardErrorCopied
线程 dump 信息说明:
- elasticsearch[Native][merge][T#1] 是我们为线程起的名字
- daemon 表示线程是否是守护线程
- prio 表示我们为线程设置的优先级
- os_prio 表示的对应的操作系统线程的优先级,由于并不是所有的操作系统都支持线程优先级,所以可能会出现都置为 0 的情况
- tid 是 Java 中为这个线程的 id
- nid 是这个线程对应的操作系统本地线程 id,每一个 Java 线程都有一个对应的操作系统线程
- wait on condition 表示当前线程处于等待状态,但是并没列出具体原因
- java.lang.Thread.State: WAITING (parking) 也是表示的处于等待状态,括号中的内容说明了导致等待的原因,例如这里的 parking 说明是因为调用了 LockSupport.park 方法导致等待
java.lang.Thread.State
一个 Thread 对象可以有多个状态,在 java.lang.Thread.State 中,总共定义六种状态。
- New:线程刚刚被创建,也就是已经 new 过了,但是还没有调用 start()方法,jstack 命令不会列出处于此状态的线程信息。
- RUNNABLE:RUNNABLE 这个名字很具有欺骗性,很容易让人误以为处于这个状态的线程正在运行。事实上,这个状态只是表示,线程是可运行的。我们已经无数次提到过,一个单核 CPU 在同一时刻,只能运行一个线程。
- BLOCKED:线程处于阻塞状态,正在等待一个 monitor lock。通常情况下,是因为本线程与其他线程公用了一个锁。其他在线程正在使用这个锁进入某个 synchronized 同步方法块或者方法,而本线程进入这个同步代码块也需要这个锁,最终导致本线程处于阻塞状态。
- WAITING:等待状态,调用以下方法可能会导致一个线程处于等待状态:Object.wait 不指定超时时间、Thread.join with no timeout、LockSupport.park #java.lang.Thread.State: WAITING (parking)。
- 例如:对于 wait()方法,一个线程处于等待状态,通常是在等待其他线程完成某个操作。本线程调用某个对象的 wait()方法,其他线程处于完成之后,调用同一个对象的 notify 或者 notifyAll()方法。Object.wait()方法只能够在同步代码块中调用。调用了 wait()方法后,会释放锁。
- TIMED_WAITING:线程等待指定的时间,对于以下方法的调用,可能会导致线程处于这个状态:
- Thread.sleep #java.lang.Thread.State: TIMED_WAITING (sleeping)
- Object.wait 指定超时时间 #java.lang.Thread.State: TIMED_WAITING (on object monitor)
- Thread.join with timeout
- LockSupport.parkNanos #java.lang.Thread.State: TIMED_WAITING (parking)
- LockSupport.parkUntil #java.lang.Thread.State: TIMED_WAITING (parking)
- TERMINATED
- 线程终止。说明,对于 java.lang.Thread.State: WAITING (on object monitor)和 java.lang.Thread.State: TIMED_WAITING (on object monitor),对于这两个状态,是因为调用了 Object 的 wait 方法(前者没有指定超时,后者指定了超时),由于 wait 方法肯定要在 syncronized 代码中编写,因此肯定是如类似以下代码导致:
synchronized(obj) { // ......... obj.wait(); // ......... }Copy to clipboardErrorCopied
死锁
在 Java 5 中加强了对死锁的检测。线程 Dump 中可以直接报告出 Java 级别的死锁,如下所示:
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x0003f334 (object 0x22c19f18, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x0003f314 (object 0x22c19f20, a java.lang.Object),
which is held by "Thread-1"Copy to clipboardErrorCopied
nid
每个线程都有一个 tid 和 nid,tid 是 Java 中这个线程的编号,而 nid(native id)是对应操作系统线程 id。有的时候,我们会收到报警,说服务器,某个进程占用 CPU 过高,肯定是因为某个 Java 线程有耗 CPU 资源的方法。
jstat
- 如下所示为 jstat 的命令格式:
$ jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]Copy to clipboardErrorCopied - 如下表示分析进程 id 为 31736 的 gc 情况,每隔 1000ms 打印一次记录,打印 10 次停止,每 3 行后打印指标头部:
$ jstat -gc -h3 31736 1000 10Copy to clipboardErrorCopied
jstat -gc
$ jstat -gc xxxxCopy to clipboardErrorCopied
其对应的指标含义如下:
| 参数 | 描述 |
|---|---|
| S0C | 年轻代中第一个 survivor(幸存区)的容量 (字节) |
| S1C | 年轻代中第二个 survivor(幸存区)的容量 (字节) |
| S0U | 年轻代中第一个 survivor(幸存区)目前已使用空间 (字节) |
| S1U | 年轻代中第二个 survivor(幸存区)目前已使用空间 (字节) |
| EC | 年轻代中 Eden(伊甸园)的容量 (字节) |
| EU | 年轻代中 Eden(伊甸园)目前已使用空间 (字节) |
| OC | Old 代的容量 (字节) |
| OU | Old 代目前已使用空间 (字节) |
| PC | Perm(持久代)的容量 (字节) |
| PU | Perm(持久代)目前已使用空间 (字节) |
| YGC | 从应用程序启动到采样时年轻代中 gc 次数 |
| YGCT | 从应用程序启动到采样时年轻代中 gc 所用时间(s) |
| FGC | 从应用程序启动到采样时 old 代(全 gc)gc 次数 |
| FGCT | 从应用程序启动到采样时 old 代(全 gc)gc 所用时间(s) |
| GCT | 从应用程序启动到采样时 gc 用的总时间(s) |
jstat -gcutil
查看 gc 的统计信息
$ jstat -gcutil xxxxCopy to clipboardErrorCopied
其对应的指标含义如下:
| 参数 | 描述 |
|---|---|
| S0 | 年轻代中第一个 survivor(幸存区)已使用的占当前容量百分比 |
| S1 | 年轻代中第二个 survivor(幸存区)已使用的占当前容量百分比 |
| E | 年轻代中 Eden(伊甸园)已使用的占当前容量百分比 |
| O | old 代已使用的占当前容量百分比 |
| P | perm 代已使用的占当前容量百分比 |
| YGC | 从应用程序启动到采样时年轻代中 gc 次数 |
| YGCT | 从应用程序启动到采样时年轻代中 gc 所用时间(s) |
| FGC | 从应用程序启动到采样时 old 代(全 gc)gc 次数 |
| FGCT | 从应用程序启动到采样时 old 代(全 gc)gc 所用时间(s) |
| GCT | 从应用程序启动到采样时 gc 用的总时间(s) |
jstat -gccapacity
$ jstat -gccapacity xxxx1Copy to clipboardErrorCopied
其对应的指标含义如下:
| 参数 | 描述 |
|---|---|
| NGCMN | 年轻代(young)中初始化(最小)的大小 (字节) |
| NGCMX | 年轻代(young)的最大容量 (字节) |
| NGC | 年轻代(young)中当前的容量 (字节) |
| S0C | 年轻代中第一个 survivor(幸存区)的容量 (字节) |
| S1C | 年轻代中第二个 survivor(幸存区)的容量 (字节) |
| EC | 年轻代中 Eden(伊甸园)的容量 (字节) |
| OGCMN | old 代中初始化(最小)的大小 (字节) |
| OGCMX | old 代的最大容量 (字节) |
| OGC | old 代当前新生成的容量 (字节) |
| OC | Old 代的容量 (字节) |
| PGCMN | perm 代中初始化(最小)的大小 (字节) |
| PGCMX | perm 代的最大容量 (字节) |
| PGC | perm 代当前新生成的容量 (字节) |
| PC | Perm(持久代)的容量 (字节) |
| YGC | 从应用程序启动到采样时年轻代中 gc 次数 |
| FGC | 从应用程序启动到采样时 old 代(全 gc)gc 次数 |
其他命令
- 查看年轻代对象的信息及其占用量。
jstat -gcnewcapacity xxxx1Copy to clipboardErrorCopied - 查看老年代对象的信息及其占用量。
jstat -gcoldcapacity xxxx1Copy to clipboardErrorCopied - 查看年轻代对象的信息
jstat -gcnew xxxx1Copy to clipboardErrorCopied - 查看老年代对象的信息
jstat -gcold xxxx
埋点与插桩
非侵入式埋点
运行时代码诊断,首先需要考虑的就是如何将埋点代码嵌入至业务代码中;常见做法主要有四种:侵入式埋点、运行时增强、编译时增强、中间件增强,后三种都属于非侵入式埋点,埋点性能逐步提升。
- 侵入式埋点:每个业务方都需要主动感知或唤起埋点代码,仅适用于小范围内部产品,不宜大范围推广。
- 运行时增强:程序运行时动态拦截,如 Spring AOP、jvm-sandbox。优点是动态可插拔,控制灵活;缺点是有运行时额外开销。
- 编译时增强:程序编译时进行增强,如 AspectJ、ASM。优点是几乎没有运行时额外开销;缺点是需要额外的构建步骤,启动比较慢。
- 中间件增强:在各个中间件服务中嵌入埋点代码。优点是原生代码,没有任何额外开销;缺点是需使用统一的中间件服务。
调用拦截
调用拦截的目的是为了明确线程监听的对象与生命周期 。传统的线程诊断,由于没有明确的监听对象与生命周期,只能进行全局线程的随机监听,不但浪费了大量的系统资源,还经常遗漏关键调用的线程信息。
性能诊断
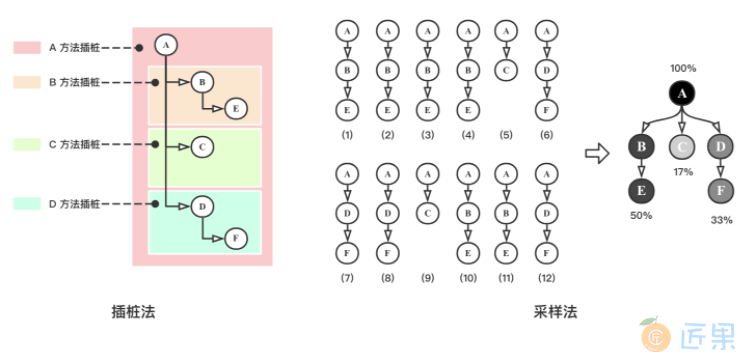
性能诊断主要有插桩(Instrumentation)和采样(Sampling)两种实现方式,前者开销较高,后者结果有一定误差。
- 插桩法(Instrumentation),需要在每个方法前后添加埋点,计算耗时,优点是结果准确,缺点是开销较高,需要明确目标函数,代码结构也会发生一定变化,很多在线诊断工具,如 Arthas 都是采用的这种方法。
- 采样法(Sampling),则是周期性获取 JVM 运行栈快照,然后通过比对方法在快照集(Snapshot Set)中出现的次数来粗略估计其运行时间。每次快照生成均需等待 JVM 运行到安全点(Safe Point),因此,运行结果有一定误差,不过,性能开销要远低于插桩法,而且能够获取完整线程栈,无需事先指定目标函数。主流的 Java Profiler 都是采用的 Sampling 方式。