到目前为止,您已经了解了如何通过浏览器调用 API 来访问特定数据。接下来,您将学习如何通过 Python 脚本进行这些调用,以及如何读取数据、存储数据并将其写入文件。
以前,我们将 Python 行直接输入到解释它们的交互式 shell 中,帮助立即传达 Python 的工作原理。但随着我们朝着更复杂的 Python 使用迈进,我们需要换档并开始使用文本编辑器来编写 Python 脚本。
您可以在计算机上预装的免费文本编辑器中编写脚本,例如 Mac 上的 TextEdit 或 Windows 上的写字板,但最好在专为开发人员设计的文本编辑器中编写和编辑代码。这些文本编辑器具有语法突出显示功能,可以为代码着色以使其更易于阅读。我推荐的一个不错的免费文本编辑器是 Atom,您可以在 https://atom.io 下载它。
编写你的第一个脚本
现在我们可以编写脚本了!让我们从组织文件开始。在令人难忘的地方创建一个文件夹并将其命名为 python_scripts。对于 Mac 和 Windows,我建议将其保存在 Documents 文件夹中。然后打开一个文本编辑器并创建一个空白文件(在 Atom 中,选择 File>New File)。
将此文件保存在您的 python_scripts 文件夹(文件>另存为...)中,名称为“youtube_script.py”。文件扩展名“.py”告诉文本编辑器文本文件中的语言是 Python。
命名文件时,一个好的经验法则是全部使用小写字母,并确保名称描述了脚本的实际作用。您不能在脚本的文件名中使用空格或以数字开头。因此,如果您的文件名很长,请使用下划线或破折号而不是空格分隔各个单词(就像我们对 youtube_script.py 所做的那样)。 Python 区分大小写,因此使用不同的大小写或拼写错误来引用同一个文件可能会导致代码损坏和很多麻烦。
现在在“youtube_script.py”中输入以下代码并保存:
print("这是我的第一个 Python 脚本!")
接下来,我们需要打开一个命令行界面 (CLI),我们在第 1 章中用它来访问 Python 交互式 shell。CLI 允许您使用代码行来浏览计算机文件。您可以将文件从一个文件夹移动到另一个文件夹、创建和删除文件,甚至可以通过它们访问 Internet。 CLI 也可以运行脚本。
运行脚本
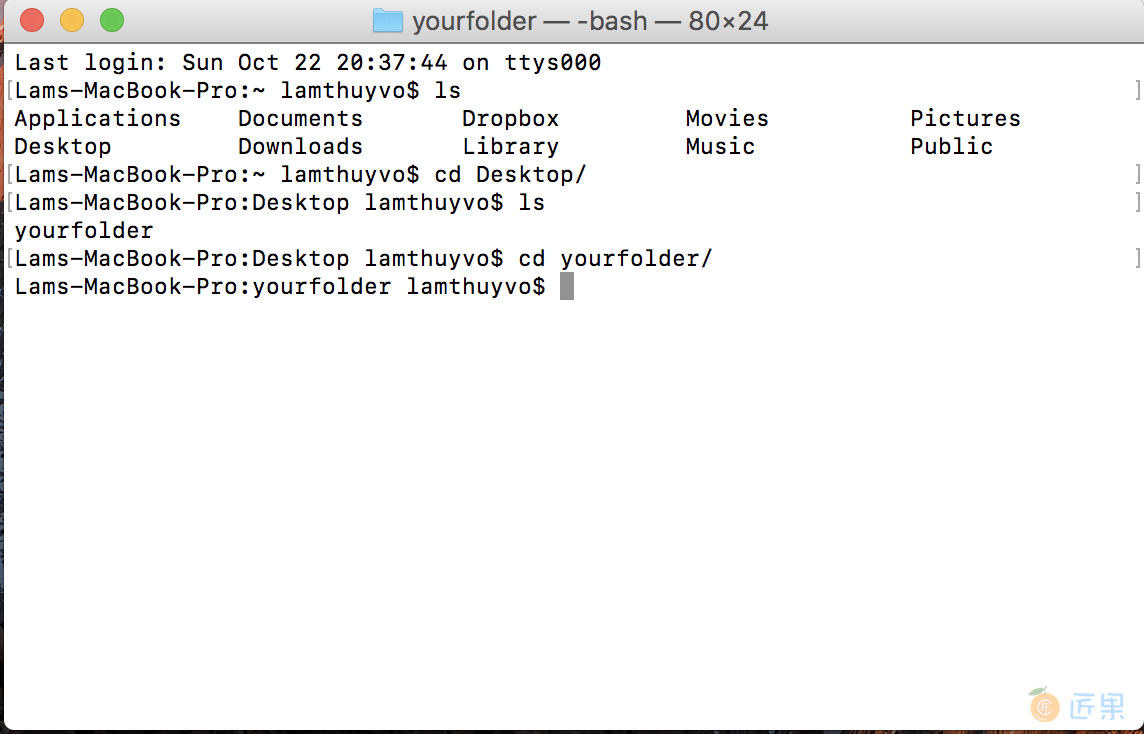
像在第 1 章中一样,使用 Mac 的终端或 Windows 的命令提示符打开 CLI。为了运行脚本,您需要导航到包含它的目录或文件夹。在 Mac 上,您可以运行 ls 命令(代表 list)来查看您在硬盘驱动器上的位置。在 Windows 上,您可以运行 dir 命令,它代表目录。当您运行这些命令时,您的 CLI 应该列出它当前所在目录中的文件,如图 3-1 所示。
现在您需要导航到您之前创建的文件夹 python_scripts。如果您习惯于使用图标导航文件夹,这可能是一个绊脚石。要在 CLI 中访问文件夹,我们需要指定文件路径,而不是单击图标,这是指向我们要访问的文件的文件夹的路径。在 Mac 上,这通常是由正斜杠分隔的文件夹名称,而在 Windows 上,它通常是硬盘驱动器的名称,后跟由反斜杠分隔的文件夹名称。例如,如果您将 python_scripts 文件夹保存在 Mac 或 Windows 上的 Documents 文件夹中,则每个文件夹的路径应分别为 Documents/python_scripts 和 C:\Documents\python_scripts。如果您将文件夹保存在其他位置,您还可以在 Finder (Mac) 或文件资源管理器 (Windows) 中导航到文件的文件夹并复制窗口中显示的路径。
要通过 CLI 导航到文件夹,请使用命令 cd(代表更改目录),后跟文件夹的路径。 例如,如果您将文件夹存储在 Mac 上的 Documents 文件夹中,请运行以下命令:
cd Documents/python_scripts
对于 Windows,您将运行以下命令:
cd C:\Documents\python_script
进入包含 Python 脚本的文件夹后,您将需要使用另一个命令来运行该脚本。 在 Mac 的 CLI 中输入以下命令:
python3 youtube_script.py
对于 Windows,请输入:
python youtube_script.py
在 Mac 上,命令 Python3 告诉您的 CLI 您将要运行用 Python(版本 3)编写的脚本,而 youtube_script.py 是您希望 CLI 运行的文件的名称和扩展名。
我们要起飞了! 运行脚本后,您应该在 CLI 中看到以下内容:
这是我的第一个 Python 脚本!
该脚本执行您在上一节中输入的 print() 函数。 现在您已经了解了如何运行脚本,让我们编写一个可以执行我们想要的脚本。
规划一个脚本
我们运行的每个脚本都会执行一系列任务。 当您第一次开始编写脚本时,您应该列出并描述这些任务以帮助组织您的想法。 这种做法有时称为伪编码。 伪编码最好用注释来完成,注释是脚本中纯粹供您或其他人阅读您的代码的行,而不是由计算机运行的。 您可以将伪编码注释视为稍后编码时将使用的待办事项列表,以提醒自己代码的每个部分应该做什么。 注释还可以作为描述性注释,帮助其他人了解您的脚本的作用。
让我们开始直接在脚本中布置待办事项列表。 通过使用井号 (#) 并写下注释在 youtube_script.py 文件中创建评论,如清单 3-1 所示。
# Import all needed libraries
# Open the URL and read the API response
# Identify each data point in your JSON and print it to a spreadsheet
清单 3-1:对脚本中要执行的步骤进行伪编码
每个标签都告诉 Python 该行的其余文本是注释。清单 3-1 在三个不同的行上有三个注释。要编写我们的脚本,我们需要首先导入一些库,它们是预先打包的代码文件。然后,我们将打开一个基于 URL 的 API 调用并读取响应,就像我们在第 2 章中所做的那样。最后,我们将返回的数据存储在一个电子表格中,以便我们可以对其进行分析。
现在我们有了一个大纲,我们可以运行每个任务并添加执行它的代码。
库和 pip
在您作为数据侦探的漫长而成功的职业生涯中,您不必编写您将使用的每个函数。正如您之前了解到的,Python 是开源的,这意味着许多开发人员编写了我们可以免费使用的函数。大多数(如果不是全部)编码人员依赖于其他人编写和发布以供他人使用的代码;这被称为编码库。当您使用 Python 处理更复杂的任务时,您需要安装和使用编码库。
有两种类型的库:
Python 标准库中包含的库——Python 附带的一组工具,当我们在计算机上安装 Python 时默认包含这些工具
第三方库,只有在我们的计算机上安装它们后才能使用
首先,让我们讨论一下 Python 自动安装并由其开发人员编写的库。以下是我们将使用的一些最常见的库:
csv 允许我们读取和写入 .csv 文件,这些文件可以作为 Excel 电子表格或 Google 表格打开。 CSV 代表逗号分隔值,这是格式化数据的常用方法。
json 使我们能够读取已格式化为 JSON 的数据。
datetime 允许我们的计算机理解和转换日期格式,并使我们能够根据需要重新格式化它们。
在我们可以使用图书馆之前,我们需要导入它,这就像在您可以阅读之前将电子书下载到平板电脑上一样。要加载库,请使用 Python 关键字 import,然后指定库的名称,例如 CSV。例如,要将 CSV 库加载到交互式 shell 中,您需要输入以下内容:
import csv
使用来自更广泛的 Python 社区的 Python 库有点棘手。 这些库中的大部分都可以在 PyPI(Python 包索引;https://pypi.python.org/pypi)上找到,您可以在该站点上浏览其他人上传以供公共使用的库的描述和代码。
获取这些库的最简单方法是通过 pip,这是一个为帮助开发人员管理其他库而编写的库(多么元!)。 您可以使用 https://pip.pypa.io/en/stable/installing/ 上的说明安装 pip。
安装 pip 后,您可以使用它来安装 PyPI 上列出的任何库。 要安装库,请在您的 CLI 中输入这个简单的公式(用 PyPI 上列出的名称替换 library_name):
pip install library_name
这些是我们在本书中使用的一些 PyPI 库:
requests允许我们使用 URL 打开网站。beautifulsoup4帮助我们阅读网站的HTML和CSS代码。pandas使我们能够解析数百万行数据,对其进行修改、应用数学运算并导出分析结果。
要遵循本书中的练习,请通过在 CLI 中依次运行以下命令来安装这些库,并在每个命令之后按 Enter(确保在执行此操作时已连接到 Internet!):
pip install requests
pip install beautifulsoup4
pip install pandas
在完成本书的练习时,我们将解决如何使用每个库。
现在我们知道如何访问库,让我们在我们的脚本中部署它们! 回到我们的 Python 脚本 youtube_script.py,让我们转到包含有关导入所有需要的库的注释的伪代码部分。 我们将使用前面提到的两个预装 Python 的库,json 和 csv。 我们还将使用我们刚刚安装的请求库,它允许我们打开 URL。 将清单 3-2 中的代码输入到 youtube_script.py 中。
import csv
import json
import requests
--snip--
清单 3-2:在我们的脚本中导入我们需要的库
你可以看到我们使用关键字 import 来加载每个库——这就是它的全部内容! 现在让我们继续执行待办事项列表中的下一个任务:打开 URL 以进行 API 调用。
Creating a URL-based API Call
为了进行 API 调用,我们将使用刚刚导入的请求库,如清单 3-3 所示。
--snip--
import requests
api_url = "https://www.googleapis.com/youtube/v3/search?part=\
snippet&channelId=UCJFp8uSYCjXOMnkUyb3CQ3Q&key=YOUTUBE_APP_KEY"①
api_response = requests.get(api_url)②
videos = json.loads(api_response.text)③
清单 3-3:使用请求库进行 API 调用
首先,我们需要创建 URL,我们通过创建变量 api_url 并将其分配给一个类似于我们在第 2 章①中使用的 URL(我们删除了包含术语 cake 的视频的参数,并将通道 ID 之前的代码段规范,稍后将在第 57 页的“存储变量中更改的值”中派上用场)。现在我们已经设置了 URL,我们可以使用 requests 库连接到互联网,进行 API 调用,并接收 API 的响应。
要访问任何库中的函数,我们需要使用库的名称来引用它——在本例中为 requests。然后我们通过在函数前面加上句点将函数链接到库名称。在这种情况下,我们将使用函数 get(),它将 URL 字符串作为参数并向该 URL 发出请求。在 Python 中,我们通过键入库名,后跟一个句点,最后是函数名来调用属于库的函数。例如 get() 函数是 requests 库的一部分,所以我们编写 requests.get() 来调用它。
我们将要访问的 URL 字符串存储在变量 api_url 中,因此我们将其传递给 get() 函数。然后,响应库为我们提供了许多接收响应的选项。然后我们将这个 API 响应存储在一个名为 api_response ② 的变量中。
最后但并非最不重要的一点是,我们从 JSON 库 ③ 中调用 load() 函数,它帮助我们将普通的 api_response 文本转换为 JSON 键和值。 load() 函数需要文本,但默认情况下,请求库返回一个 HTTP 状态代码,它通常是一个编号的响应,例如 200 表示工作网站或 404 表示未找到的网站。我们需要访问响应的文本,或者在这种情况下访问我们数据的 JSON 渲染。我们可以通过在 api_response 变量后面加一个句点,然后是选项 .text 来实现。因此整个结构看起来像这样:json.loads(api_response.text) ③。这会将 API 调用的响应转换为 Python 脚本的文本,以将其解释为 JSON 键和值。我们将在本章的下一节中更仔细地查看这行代码以及它的作用。
如您所见,我们在此脚本中使用了许多描述性变量。这有助于我们将脚本分解成我们能够清楚跟踪的部分。
在电子表格中存储数据
好的,我们的伪代码待办事项列表的第 1 项和第 2 项已经完成——我们已经导入了我们的库并收到了 API 响应。是时候进行下一步了:从 JSON 中检索数据点以放入电子表格。为此,我们将使用 csv 库。不过,首先让我们看看如何创建 .csv 文件并向其中写入信息。将清单 3-4 中的代码输入到您的 Python 脚本中。
--snip--
videos = json.loads(api_response.text)
with open("youtube_videos.csv", "w") as csv_file:①
csv_writer = csv.writer(csv_file)②
csv_writer.writerow(["publishedAt",③
"title",
"description",
"thumbnailurl"])
清单 3-4:创建 .csv 文件的标题
要创建 .csv 文件,我们使用 open() 函数①,该函数内置于 Python 中,并根据提供给它的参数打开或创建一个文件。 open() 函数接受两个字符串作为参数,每个字符串用逗号分隔。第一个参数是我们要创建或打开的 .csv 文件的名称,在本例中为“youtube_videos_posts.csv”。第二个参数指定我们是要读取文件(“r”),写入文件并删除之前的所有内容(“w”),还是简单地向文件添加更多内容(“a”)。在这种情况下,我们要编写一个全新的文件。虽然 open() 函数听起来只能打开文件,但它也足够聪明,可以检查名称与第一个参数匹配的文件是否已经存在。如果 open() 函数没有找到,Python 将知道创建一个新的 .csv 文件。接下来,我们需要将文件分配给一个变量,以便我们可以在代码中引用该文件。
您可能会注意到,我们没有使用等号将文件直接分配给变量,而是在 with 语句中使用 open() 函数。 with 语句打开一个文件并在我们完成修改后自动关闭它。我们通过编写关键字 with 来构造一个 with 语句,然后是 open() 函数。然后我们使用单词 as 后跟一个变量名,比如 csv_file,我们将用它来指代我们正在打开的文件。 with 语句以冒号结尾,就像你学过的其他类型的语句一样。在冒号之后,Python 需要缩进的代码行,详细说明要对文件执行的一组操作。一旦 Python 执行了这些操作并且代码被取消缩进,with 语句将关闭文件。
接下来我们使用 CSV 库的 writer() 函数打开 .csv 文件,该函数允许我们将数据行写入文件②。为简单起见,我们将从仅写入一行数据开始。 writer() 函数需要一个 .csv 文件作为参数,因此我们将它传递给 csv_file。我们将所有这些存储在变量“csv_writer”中。最后,我们使用 writerow() 函数将第一行写入 .csv 文件,该函数将字符串列表作为参数 ③。第一行数据应该是我们电子表格的标题列表,描述每行将包含的内容类型。
现在我们有一个带有标题的电子表格,是时候从 API 响应中获取数据并将其写入 .csv 文件了!
对于这项任务,我们将部署我们在第 1 章中首次遇到的可信赖的老朋友 for 循环。 正如我们所知,JSON 数据来自包含各种数据点的大括号组,每个数据点成对出现键和值。我们之前使用了 for 循环来循环遍历列表中的数据。现在,我们将使用一个循环遍历与每个帖子关联的数据,并使用每个数据点的键访问数据值。
为了做到这一点,首先我们需要看看 JSON 数据在 Python 中是如何组织的。让我们回到前面的代码,当我们加载 JSON 时,如清单 3-5 所示。
--snip--
api_response = requests.get(api_url)
videos = json.loads(api_response.text)①
--snip--
清单 3-5:加载 JSON 数据
您可能还记得,循环需要一个项目列表。 在这种情况下,我们将所有 YouTube 视频的列表作为 JSON 对象。 我们之前在脚本①中将这些帖子存储到视频变量中。 现在,我们可以使用 for 循环选择视频,但是为了访问我们想要的帖子信息,我们需要浏览 JSON 对象的结构并查看 load() 函数的作用。
将 JSON 转换为字典
当 Python 使用 json.load() 函数加载 JSON 时,它会将 JSON 数据转换为 Python 字典。 字典类似于列表,但它不是简单地存储多个值,而是将值存储在键值对中——就像 JSON! 让我们通过一个例子来看看这是如何工作的。
启动交互式 Python shell,然后输入以下内容:
>>> cat_dictionary = {"cat_name": "Maru", "location": "Japan"}
如您所见,我们正在使用变量 cat_dictionary。 然后我们用键名 cat_name 和 location 创建了一个字典,并将它们分别与值 Maru 和 Japan 配对。 按 Enter 键后,交互式 shell 会将这个字典分配给变量 cat_dictionary。 到现在为止还挺好。 但是如何访问每个数据项呢?
请记住,每个键都与一个值相关联。 因此,要访问使用键存储的数据值,首先我们需要键入存储字典的变量的名称,然后键入方括号内的字符串形式的键名称。 例如,如果我们想访问使用键“cat_name”存储的字符串“Maru”,我们将键入以下内容:
>>> cat_dictionary["cat_name"]
>>> 'Maru'
现在让我们使用脚本访问存储的 JSON 数据。
回到脚本
每个网站都有组织成键值对的 JSON 对象,但并非每个网站都会使用相同的键名或整体 JSON 结构。 在第 2 章中,您看到 YouTube 的 JSON 的组织方式如清单 3-6 所示。
"items"①: [
{
"kind": "youtube#searchResult",
"etag": "\"XI7nbFXulYBIpL0ayR_gDh3eu1k/wiczu7uNikHDvDfTYeIGvLJQbBg\"",
"id": {
"kind": "youtube#video",
"videoId": "P-Kq9edwyDs"
},
"snippet": {
"publishedAt": "2016-12-10T17:00:01.000Z",
"channelId": "UCJFp8uSYCjXOMnkUyb3CQ3Q",
"title": "Chocolate Crepe Cake",
"description": "Customize & buy the Tasty Cookbook here: http://bzfd.it/2fpfeu5 Here is what you'll need! MILLE CREPE CAKE Servings: 8 INGREDIENTS Crepes 6 ...",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/P-Kq9edwyDs/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/P-Kq9edwyDs/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/P-Kq9edwyDs/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "Tasty",
"liveBroadcastContent": "none"
}
},
{
"kind": "youtube#searchResult",
"etag": "\"XI7nbFXulYBIpL0ayR_gDh3eu1k/Fe41OtBUjCV35t68y-E21BCpmsw\"",
"id": {
"kind": "youtube#video",
"videoId": "_eOA-zawYEA"
},
"snippet": {
"publishedAt": "2016-02-25T22:23:40.000Z",
"channelId": "UCJFp8uSYCjXOMnkUyb3CQ3Q",
"title": "Chicken Pot Pie (As Made By Wolfgang Puck)",
"description": "Read more! - http://bzfd.it/1XPgzLN Recipe! 2 pounds cooked boneless, skinless chicken, shredded Salt Freshly ground black pepper 4 tablespoons vegetable ...",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/_eOA-zawYEA/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/_eOA-zawYEA/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/_eOA-zawYEA/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "Tasty",
"liveBroadcastContent": "none"
}
},
--snip--
清单 3-6:YouTube 的 JSON 数据结构
在 YouTube 的情况下,所有视频数据都包含在“items”键①下的值中。 这意味着为了访问任何视频信息,您需要通过使用括号和引号选择项目来导航到“项目”键的值:videos[‘items’]。 您可以对 Python 字符串使用双引号或单引号,因此“items”与“items”相同。
将清单 3-7 中的循环添加到您自己的脚本中。
*注意 这个片段显示了缩进的代码,因为它仍然在我们在清单 3-4 中开始编写的 with open() 语句的范围内。
--snip--
if videos.get("items") is not None:①
for video in videos.get("items"):②
video_data_row = [
video["snippet"]["publishedAt"],
video["snippet"]["title"],
video["snippet"]["description"],
video["snippet"]["thumbnails"]["default"]["url"]
]③
csv_writer.writerow(video_data_row)④
清单 3-7:使用 for 循环将数据写入 .csv 文件
首先,我们创建一个 if 语句,指示我们的代码仅在 API 调用确实返回我们的视频项目时才收集信息。如果 API 调用没有返回带有“items”键的 JSON 结构,.get() 函数将返回 None(这有助于我们避免在我们可能达到 YouTube 允许的数据量限制时可能会中断我们的脚本的错误)我们聚集)①。然后我们缩进代码并创建一个 for 循环并使用videos.get("items")②访问发布数据。现在我们已经设置了循环,我们可以循环播放每个视频并将其数据点存储为列表。一旦我们有了数据点列表,我们就可以将完整列表写入“.csv”文件。我们需要每个数据点与我们之前在脚本中创建的电子表格标题的顺序完全匹配,否则数据将无法正确组织。这意味着该列表需要按顺序包含视频的发布日期、标题、描述和缩略图 URL。
由于每个帖子也被组织到一个字典中,我们通过通过其键选择每个值来创建列表:video["snippet"]["publishedAt"]。然后我们将值放入列表③中。最后但并非最不重要的一点是,我们可以使用 writerow() 函数 ④ 将每一行写入我们的电子表格,就像我们在编写电子表格标题时所做的那样。当您运行脚本时,for 循环将为 JSON 对象中的每个帖子运行此代码。
运行完成的脚本
完成的脚本应该类似于清单 3-8。
import csv
import json
import requests
api_url = "https://www.googleapis.com/youtube/v3/search?part=snippet&channelId=UCJFp8uSYCjXOMnkUyb3CQ3Q&key=YOUTUBE_APP_KEY"
api_response = requests.get(api_url)
videos=json.loads(api_response.text)
with open("youtube_videos.csv", "w", encoding="utf-8") as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(["publishedAt",
"title",
"description",
"thumbnailurl"])
if videos.get("items") is not None:
for video in videos.get("items"):
video_data_row = [
video["snippet"]["publishedAt"],
video["snippet"]["title"],
video["snippet"]["description"],
video["snippet"]["thumbnails"]["default"]["url"]
]
csv_writer.writerow(video_data_row)
清单 3-8:功能脚本
恭喜! 我们已经正式编写了一个脚本,可以为我们从 API 中收集数据。
现在您的脚本已准备就绪,请保存它,然后按照第 44 页上的“运行脚本”中的说明尝试运行它。运行脚本后,您应该在与 你的脚本。 当您在电子表格程序中打开该文件时,它应该包含类似于图 3-2 的 YouTube 视频数据。
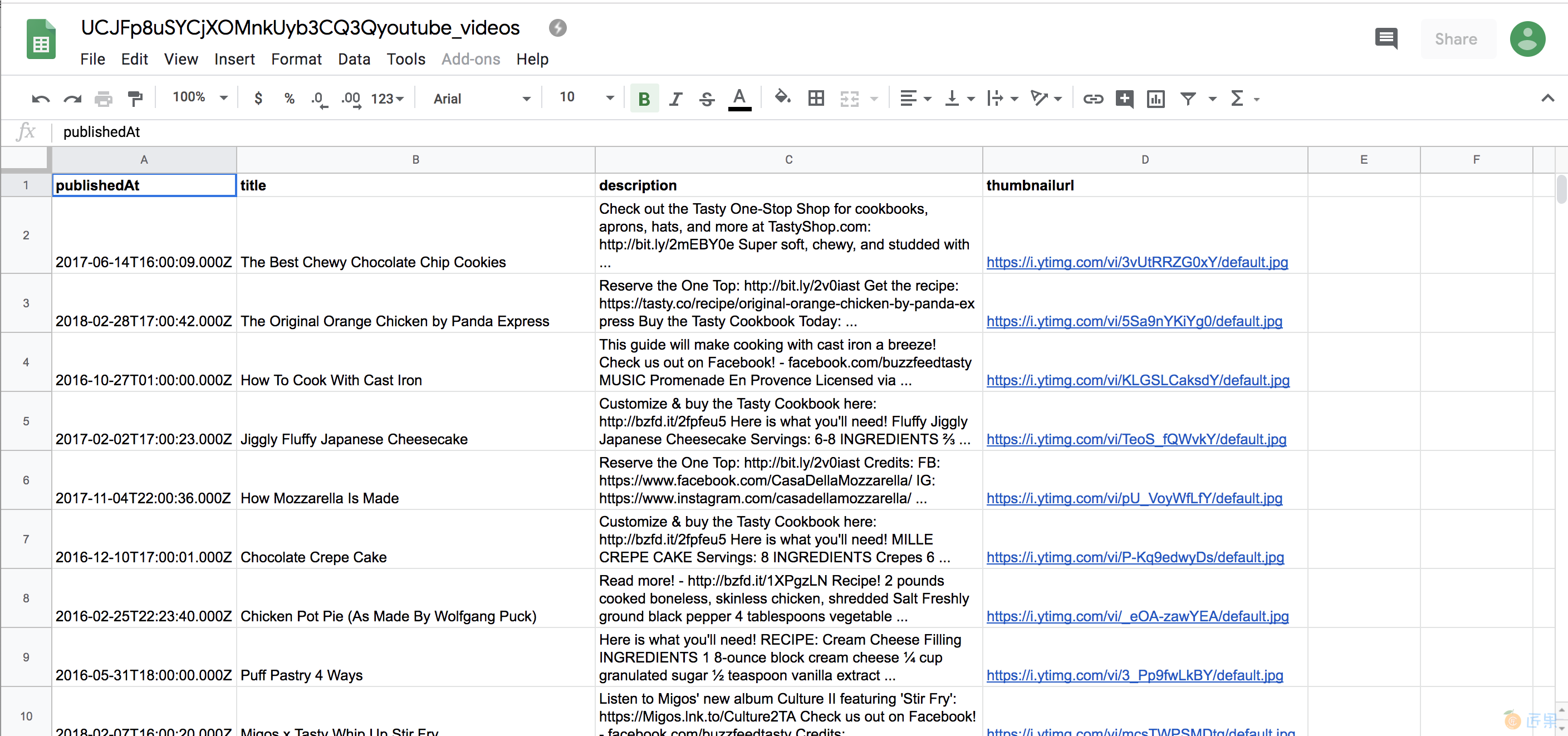
图 3-2:我们的电子表格在上传到 Google 表格等电子表格程序后的外观
虽然此脚本可能仅适用于 YouTube API,但它演示了编写可从其他平台收集数据的脚本所需的基本概念。进行基于 URL 的 API 调用、读取和访问 JSON 并将其写入 .csv 文件是您将在许多数据收集和 Web 开发任务中反复使用的核心技能。
处理 API 分页
我们现在已经通过一个 API 调用触及了数据收集的一些基本方面,但是如果您检查刚刚创建的电子表格,您可能会注意到 .csv 文件仅包含少数帖子的数据。
欢迎来到无处不在的社交媒体数据所带来的问题!由于加载数百或数千个 YouTube 视频会使站点的服务器紧张,因此我们无法一次请求所需的所有数据。根据我们请求的数据点数量,我们甚至可能使页面或服务器崩溃。为了防止这种情况发生,许多 API 提供者构建了减慢数据获取过程的方法。
YouTube 限制了我们可以通过分页请求的数据,将数据分成多个 JSON 对象。把它想象成包含数千个条目的电话簿(来自过去)。您可以翻阅一本多页的书,而不是将所有条目放在一个很长的页面上。
在本练习中,您需要进一步探索 YouTube 的 JSON 对象。我们已经进入了一个部分,我们通过使用“数据”键使用posts[“data”]来访问它。如果我们更仔细地查看我们一直在使用的 JSON 对象,我们会在所有发布数据之后看到第二个键,称为“分页”,如清单 3-9 所示。
{
"kind": "youtube#searchListResponse",
"etag": "\"XI7nbFXulYBIpL0ayR_gDh3eu1k/WDIU6XWo6uKQ6aM2v7pYkRa4xxs\"",
"nextPageToken": "CAUQAA",
"regionCode": "US",
"pageInfo": {
"totalResults": 2498,
"resultsPerPage": 5
},
"items": [
{
"kind": "youtube#searchResult",
"etag": "\"XI7nbFXulYBIpL0ayR_gDh3eu1k/wiczu7uNikHDvDfTYeIGvLJQbBg\"",
"id": {
"kind": "youtube#video",
"videoId": "P-Kq9edwyDs"
},
--snip--
清单 3-9:JSON 对象中的分页数据
当我们运行我们的脚本时,它只检索页面上的“items”键中的内容,因此要访问更多结果,我们需要打开下一页。 如清单 3-9 所示,API 响应呈现更多 JSON 数据,可通过键“nextPageToken”访问,并包含另外两个字典。
要访问下一页,我们可以使用随“nextPageToken”键提供的令牌。 我们如何使用这个值? 每个 API 处理分页的方式不同,因此我们应该查阅 YouTube API 文档。 我们了解到要跳转到下一页结果,我们需要向 API URL 添加一个名为“pageToken”的新参数,并为其分配由“nextPageToken”键提供的值。 修改您的脚本,如清单 3-10 所示。
--snip--
csv_writer.writerow(["publishedAt",
"title",
"description",
"thumbnailurl"])
has_another_page = True①
while has_another_page:②
if videos.get("items") is not None:
for video in videos.get("items"):
video_data_row = [
video["snippet"]["publishedAt"],
video["snippet"]["title"],
video["snippet"]["description"],
video["snippet"]["thumbnails"]["default"]["url"]
]
csv_writer.writerow(video_data_row)
if "nextPageToken" in videos.keys():
next_page_url = api_url + "&pageToken="+videos["nextPageToken"]③
next_page_posts = requests.get(next_page_url)
videos = json.loads(next_page_posts.text)④
else:
print("no more videos!") has_another_page = False⑤
清单 3-10:修改脚本以从其他页面收集数据
首先我们引入一个名为 has_another_page 的变量,我们为其赋值 True ①。我们将使用这个变量来检查是否还有另一个页面可以获取数据。这是许多开发人员在条件语句中使用的一个技巧,就像我们在第 1 章中学到的 if 子句一样。 while 语句②是一种循环类型,它接受一个条件,就像一个 if 语句,并运行其中的代码直到条件成立给它是假的。我们将在 while 语句中使用 has_another_page 变量,并在到达数据流的末尾并且没有剩余页面时将其切换为 False ⑤。脚本的前几行与我们在示例 3-8 中编写的行相同,除了我们现在将它们嵌套在 while 循环中。 while 循环第一次运行时,它会像以前一样在第一个 JSON 页面上收集数据。
一旦我们遍历了第一页上 JSON 中的每个数据对象,我们就会检查 JSON 是否包含“nextPageToken”键的值。如果不存在 "nextPageToken" 键,则脚本没有其他页面可供加载。如果“nextPageToken”键确实存在,我们会将视频[“nextPageToken”] 链接的字符串存储在名为“next_page_url③”的变量中。这对应于数据项 "nextPageToken": "CAUCQAA",我们在清单 3-9 的 "nextPageToken" 下看到了它。我们将使用此 URL 执行另一个基于 URL 的 API 调用④,并将响应存储在 posts 变量中。加载下一页帖子后,我们返回到循环的开头并收集下一组帖子数据。
这个循环将一直运行,直到我们到达 JSON 输出的结尾(换句话说,我们的“电话簿”的结尾)。一旦 API 不再显示 videos["nextPageToken"] 的值,我们就会知道我们已经到达最后一页。那就是当我们将变量 has_another_page 分配给 False ⑤ 并结束循环时。
我们在本练习中涵盖的内容非常适合初学者学习,因此如果您需要重新阅读,请不要太担心。要带走的主要概念是,这就是分页通常的工作方式以及我们作为开发人员必须如何解决它们:因为数据提供者限制了我们可以通过每个 API URL 获得的数据量,我们必须以编程方式“离开”我们被允许访问的不同数据页面。
模板:如何使您的代码可重用
我们已经完成了我们来到这里的目的:我们得到了我们的数据——而且很多!可是等等!现在我们需要采取额外的步骤并以使其可重用的方式清理我们的代码。换句话说,我们希望对代码进行模板化,或者将脚本变成可以反复使用的模板。
这意味着什么?好吧,我们需要一个不仅可重用而且足够灵活以适应不同类型场景的脚本。要对我们的脚本进行模板化,首先我们要看看在重新利用它时我们可能想要更改它的哪些部分。
我们想要更改的是我们的凭据(如果我们想将代码提供给其他人)、我们想要访问的 YouTube 频道以及我们想要收集的数据类型。当我们在紧迫的期限内工作并且经常重复任务时,或者当我们倾向于对我们想要用于研究的信息类型进行大量试验时,这尤其有用。
存储在变量中发生变化的值
让我们的代码更灵活的一种方法是将参数设置为我们在脚本开头定义的变量。这样,所有可更改的代码片段都组织在一个易于查找的地方。一旦我们定义了每个变量,我们就可以将它们重新拼接在一起以形成我们的 API 调用。看看代码清单 3-11,看看它是如何工作的。
--snip--
import csv
import json
import requests
channel_id = "UCJFp8uSYCjXOMnkUyb3CQ3Q"
youtube_api_key = "XXXXXXX"②
base = "https://www.googleapis.com/youtube/v3/search?"③
fields = "&part=snippet&channelId="④
api_key = "&key=" + youtube_api_key⑤
api_url = base + fields + channel_id + api_keyz
api_response = requests.get(api_url)
posts = json.loads(api_response.text)
--snip--
清单 3-11:模板化脚本以供重用
在顶部,我们定义了另外两个变量:与感兴趣的 YouTube 频道 ① 相关联的 channel_id 和用于将我们的 API 密钥存储为字符串 ② 的 youtube_api_key 变量。您还可以看到我们将 API URL 分解为单独的部分。首先,我们定义我们的 API 的基础,它总是相同的,并将其存储在变量 base ③ 中。然后我们将 API 的字段参数作为单独的字符串输入,并将它们存储在变量字段 ④ 中。接下来,我们将 YouTube API 密钥 youtube_api_key 连接成一个字符串,该字符串存储在一个名为 api_key ⑤ 的变量中。
最后,我们将这些部分重新拼接成一个长字符串,构成我们基于 URL 的 API 调用 z。此过程允许我们在将来修改 API 调用的部分内容,以防我们想向查询添加其他参数或使用不同的凭据来访问 API。
将代码存储在可重用的函数中
另一种可以模板化代码的方法是将其包装到一个可以反复调用的函数中,如清单 3-12 所示。
def make_csv(page_id):①
base = "https://www.googleapis.com/youtube/v3/search?"
fields = "&part=snippet&channelId="
api_key = "&key=" + youtube_api_key
api_url = base + fields + page_id + api_key
api_response = requests.get(api_url)
videos = json.loads(api_response.text)
with open("%syoutube_videos.csv" % page_id, "w") as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(["post_id",
"message",
"created_time",
"link",
"num_reactions"])
has_another_page = True
while has_another_page:
if videos.get("items") is not None:
for video in videos.get("items"):
video_data_row = [
video["snippet"]["publishedAt"],
video["snippet"]["title"],
video["snippet"]["description"],
video["snippet"]["thumbnails"]["default"]["url"]
]
csv_writer.writerow(video_data_row)
if "nextPageToken" in videos.keys():
next_page_url = api_url + "&pageToken="+videos["nextPageToken"]
next_page_posts = requests.get(next_page_url)
videos = json.loads(next_page_posts.text)
else:
print("no more videos!")
has_another_page = False
清单 3-12:将代码放入 make_csv() 函数中
在这里,我们将所有代码包装到一个名为 make_csv() 的函数中,该函数采用参数 page_id。 正如我们在第 1 章中所讨论的,函数是一种在代码中布置一系列步骤的方法,我们可以通过稍后调用该函数来重复运行这些步骤。 首先,我们声明 make_csv() 函数并指定我们希望它采用的任何参数①,然后我们输入我们希望包含在该函数中的所有代码。 你想要包含在 make_csv() 中的所有内容都需要在函数声明下缩进,以便 Python 知道哪个代码是函数的一部分。 现在我们已经定义了 make_csv(),我们可以通过调用它的名称并在函数的括号中传递一个参数来执行它。
最终的可重用脚本应如清单 3-13 所示。
import csv
import json
import requests
channel_id = "UCJFp8uSYCjXOMnkUyb3CQ3Q"①
channel_id2 = "UCpko_-a4wgz2u_DgDgd9fqA"②
youtube_api_key = "XXXXXXX"
def make_csv(page_id):③
base = "https://www.googleapis.com/youtube/v3/search?"
fields = "&part=snippet&channelId="
api_key = "&key=" + youtube_api_key
api_url = base + fields + page_id + api_key
api_response = requests.get(api_url)
videos = json.loads(api_response.text)
with open("%syoutube_videos.csv" % page_id, "w") as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(["publishedAt",
"title",
"description",
"thumbnailurl"])
has_another_page = True
while has_another_page:
if videos.get("items") is not None:
for video in videos.get("items"):
video_data_row = [
video["snippet"]["publishedAt"],
video["snippet"]["title"],
video["snippet"]["description"],
video["snippet"]["thumbnails"]["default"]["url"]
]
csv_writer.writerow(video_data_row)
if "nextPageToken" in videos.keys():
next_page_url = api_url + "&pageToken="+videos["nextPageToken"]
next_page_posts = requests.get(next_page_url)
videos = json.loads(next_page_posts.text)
else:
print("no more videos!")
has_another_page = False
make_csv(channel_id)④
make_csv(channel_id2)⑤
清单 3-13:完整的模板脚本
我们使用变量 channel_id ① 和 channel_id2 ② 来保存脚本中最有可能改变的部分。然后我们定义 make_csv() 函数,它保存我们要运行的代码③。现在我们可以通过将 channel_id ④ 和 channel_id2 ⑤ 变量传递给 make_csv() 函数来运行该函数。就是这样!
还有两点需要注意。首先,YouTube 限制了免费帐户每天可以进行的 API 调用量。这称为速率限制。通过这种 API 调用,我们每个频道只能获得几百个视频,所以如果一个频道有很多视频——比我们通过免费帐户获得的还要多——我们可能需要使用不同的 API 凭证来获取数据第二个频道。其次,在线生成的内容可能包含不同类型的特殊字符——例如表情符号或不同语言的字符——这些字符可能很难被特定版本的 Python 理解,或者如编码人员所说,难以编码。在这些情况下,Python 可能会返回一个 UnicodeEncodeError,这是一个通知,表示 Python 遇到了它在读取和写入时遇到问题的内容。
注意 Unicode (https://unicode.org/) 是一种规范,旨在通过为每个字符分配自己的代码来表示书面人类语言中使用的每个字符,例如字母或表情符号。将其视为您计算机的查找表。
虽然这不是我在 Mac 计算机上运行脚本时遇到的错误,但 Windows 计算机似乎在对我们尝试通过 API 调用摄取的某些内容进行编码时存在问题。由于 API 调用会返回一些可从任何给定平台获得的最新数据,因此对 API 调用的每个响应都将特定于来自 API 提供者的最新信息。这也意味着,如果您遇到与您尝试通过此 API 访问的内容相关的错误,您将需要找到与该特定内容密切相关的解决方案。为确保您收到正确的结果,为您尝试收集的数据指定一种编码方法可能会有所帮助。清单 3-14 显示了脚本的一个小修改,可以帮助解决一些特定类型数据的问题。
--snip--
video_data_row = [
video["snippet"]["publishedAt"]
video["snippet"]["title"].encode("utf-8")①,
video["snippet"]["description"].encode("utf-8")②,
video["snippet"]["thumbnails"]["default"]["url"].encode("utf-8")③
]
清单 3-14:修改脚本以帮助检索正确的结果
在这段代码中,我们将 .encode() 函数添加到我们通过不同键访问的三个值中:标题,我们通过 video["snippet"]["title"] ① 访问;视频的描述,我们通过video["snippet"]["description"]②访问;以及视频的链接,我们可以通过 video["snippet"]["thumbnails"]["default"]["url"] ③ 访问该链接。在 .encode() 函数的括号内,我们指定要使用哪种编码方法来更好地理解数据。在这种情况下,我们使用一种称为 utf-8 的通用编码类型(UTF 代表 Unicode 转换格式,8 只是指定我们使用 8 位值来编码我们的信息)。请注意,虽然此方法可能会解决一些编码问题,但由于每个错误都特定于您尝试收集的内容,因此可能值得阅读其他潜在的解决方案。 (您可以在 https://docs.python.org/3/howto/unicode.html 找到有用的教程。)
创建模板代码后,我们可以将其用于我们想要的任何 YouTube 频道。我们现在可以为多个页面运行 make_csv() 函数或使用不同的凭据。我们需要做的就是更改与 channel_id 和 channel_id2 变量或 youtube_api_key 变量关联的字符串。
在您起草完成目标的脚本之后,模板化您的代码是一个很好的做法。这允许您改进您的代码,重复您已经编程的任务,并与可能使用它们的其他人共享您的脚本——我们使用其他人的代码,那么为什么不回报呢?
概括
本章向您展示了 API 的工作原理以及如何使用脚本从中挖掘数据。 API 是收集数据的重要工具。知道如何利用它们以及如何修改脚本比脚本本身更重要。那是因为脚本很快就会过时。社交媒体公司提供数据的方式一直在变化——他们可能会实施限制数据访问的新政策,就像 Facebook 在 2015 年所做的那样,关闭了对朋友数据的访问。或者公司可能只是改变他们允许用户与其 API 交互的方式,就像 Instagram 在 2013 年停止访问其照片流时所做的那样。
要了解有关脚本的更多信息,请访问 https://github.com/lamthuyvo/social-media-data-scripts,其中包含用于社交媒体数据收集、使用说明以及其他资源的链接。
在下一章中,您将了解如何从 Facebook 获取数据并将其转换为计算机可以理解的格式。