社交媒体正在成为我们生活和记忆的数字保险库;它的服务器存储了我们的行为历史,使我们能够以难以置信的精确度记住重要事件。许多社交媒体平台允许我们将社交媒体历史档案下载为数据文件或 HTML 网页。这些档案可能包含来自我们 Facebook 时间线的帖子、我们彼此发送的消息或我们发布的每条推文。
在本章中,您将学习如何使用 Python 使用自动抓取工具从我们可下载的 Facebook 档案中获取数据。抓取器遍历包含我们想要收集的信息的每个 HTML 元素,提取这些信息,按行组织它,然后将每一行数据写入列表或电子表格,就像我们在第 3 章中编写 API 时所做的那样. 但这次我们将使用稍微不同的方法来填充我们的电子表格:在将数据写入 .csv 文件之前,我们将使用数据字典来构建我们的数据。这是一种非常有用且被广泛采用的数据组织方式,它将扩展您对我们在上一章中使用的 CSV 库的知识。
你的数据源
从您注册帐户的那一天起,大多数(如果不是全部)社交媒体公司就开始存储有关您的数据。您可以通过在 Facebook 和 Twitter 时间线或 Instagram 提要上向后滚动来查看其中一些数据。
尽管大多数平台允许用户下载大量个人数据,但往往不清楚这些数据存档的完整性。社交媒体公司决定他们想要向用户发布多少和什么样的数据,就像他们决定他们想要通过 API 公开发布多少数据一样。最重要的是,弄清楚如何下载您自己的数据存档可能有点棘手:选项可能隐藏在我们用户设置的细则中,并且通常在视觉上无法区分。
对数据档案的访问因平台而异,并且可能非常细化或类似稀疏。 2018 年 5 月,欧盟的通用数据保护条例 (GDPR) 生效,要求世界各地的公司保护用户的隐私,部分原因是让他们对自己的数据有更多的控制权。虽然引入这些法律主要是为了让欧盟的用户受益,但许多社交媒体公司已经为任何人(无论是否在欧洲)下载和查看自己的数据创造了更简单的途径。
在本章中,我们将仅利用可下载社交媒体档案中公开可用的数据。您将了解网络抓取,即从网络收集和存储数据的过程。每个网站都有其独特的数据挑战。出于本教程的目的,我们将研究如何从 Facebook 抓取数据,Facebook 是最受欢迎的全球平台之一,并提供各种格式供我们分析。如果您没有 Facebook 帐户,您可以在此处找到一个示例文件进行抓取:https://github.com/lamthuyvo/social-media-data-book。
下载你的 Facebook 数据
首先我们需要下载我们的数据。许多社交媒体网站都包含下载档案的说明,但它们可能隐藏在网站的深处。查找档案的一种简单方法是将此公式输入到您选择的搜索引擎中:平台/语言 + 动词 + 对象。例如,要查找您的 Facebook 档案,您可以搜索“Facebook 下载档案”或“Python 抓取 Facebook 档案”。
要下载您的 Facebook 档案,请按照以下步骤操作:
- 单击任何 Facebook 页面右上角的向下箭头,然后选择设置。
- 在左侧边栏上,单击常规帐户设置下方的您的 Facebook 信息。
- 导航到下载您的信息,然后单击查看。
- 这应该会打开一个新页面,其中包含创建包含存档文件的选项。保留默认设置(日期范围:我的所有数据;格式:HTML;媒体质量:中等)。单击创建文件。
接下来,系统会提示您输入您的帐户凭据(确认您的密码),然后 Facebook 会通过电子邮件向您发送可下载文件的链接。
存档应下载为 ZIP 文件。将此文件放在您将用于与此项目相关的所有文件的文件夹中。解压下载的文件,您应该会在名为 facebook- 的文件夹中看到多个文件和文件夹。就我而言,此文件夹称为 facebook-lamthuyvo。
双击名为 index.html 的文件,您的默认浏览器应该会打开该页面。在您的浏览器中,您应该会在菜单左侧看到您下载的信息(广告、消息、朋友等)的类别,在右侧看到您的帐户信息概览,如图 4-1 所示.

此文件夹代表的档案比您在线滚动 Facebook 帐户时可能看到的档案更完整。在这里,您会找到诸如您曾经在 Facebook 注册的所有电话号码、与 Facebook 用来标记您和您的朋友的面部识别数据相关联的代码以及您在过去三年中点击的广告等信息个月。存档个人资料页面应该让您了解 Facebook 为自己的目的存储的有关您的活动和在线状态的信息类型。
查看数据并检查代码
为了介绍抓取的过程,我们将首先查看您在过去三个月中点击过的广告。
刮刮通常按以下方式进行:
- 查看 Web 浏览器中信息的视觉显示。
- 检查包含此信息的代码。
- 指示您的抓取工具从此代码中获取信息。
- 因此,首先,在您的 Facebook 档案的 ads 文件夹中,打开 adsrs_youve_interacted_with.html,该页面包含您在过去三个月内点击的每个广告的标题和时间戳。
查看完广告数据后,就可以进行第二步:检查代码。为此,我们将使用 Chrome 的内置开发人员工具(我们在第 1 章中了解了这些)。首先右键单击列出的广告之一,然后在打开的下拉列表中选择“检查”。当 Web Inspector 打开时,它应该突出显示代表您刚刚右键单击的广告的代码。图 4-2 显示了 Chrome 中的 Web Inspector 视图。
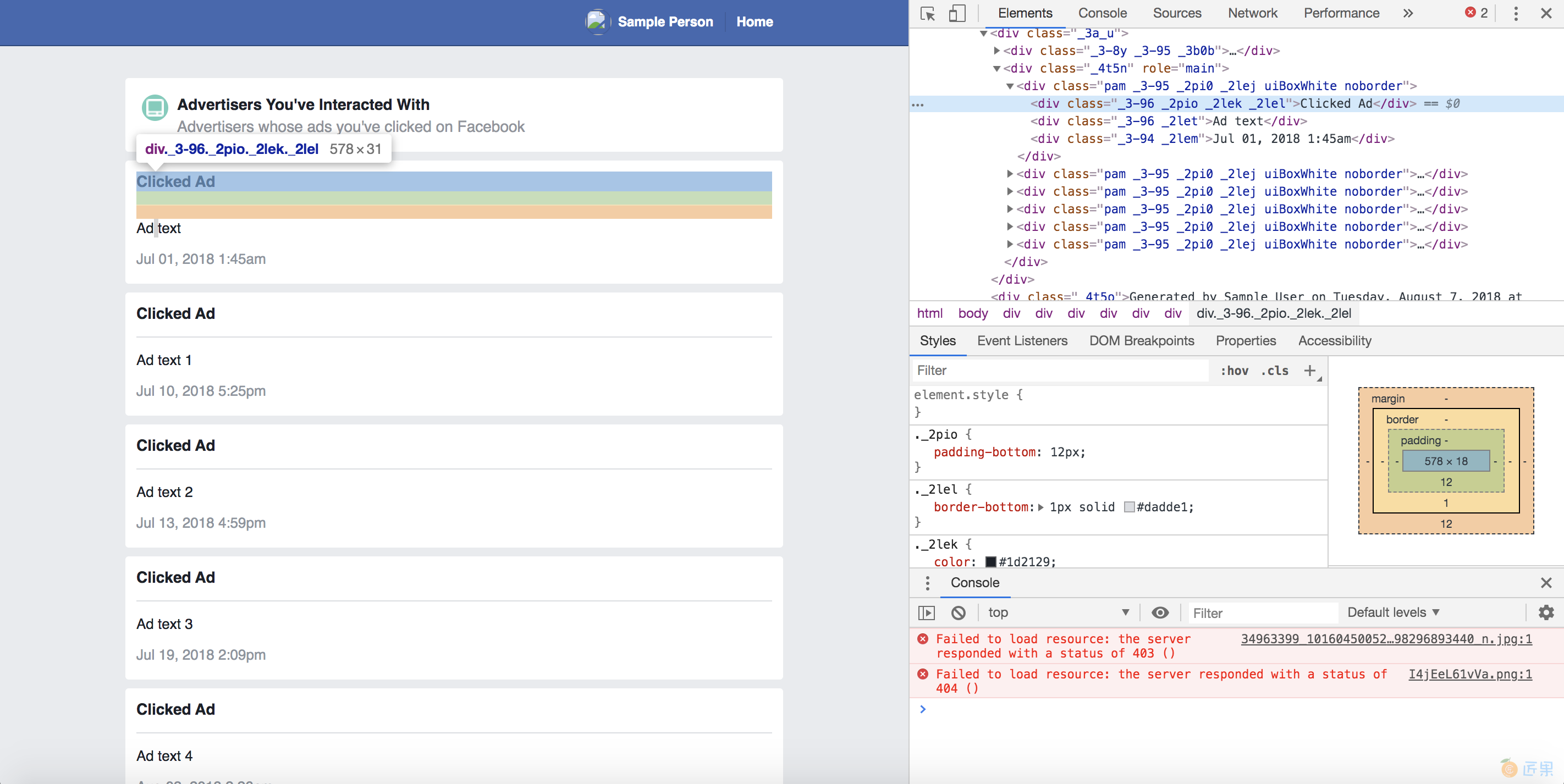
回想一下,网页是 HTML 文件,其中包含使用 CSS ID 和类样式化的 HTML 标签内的信息。 当一个页面呈现重复的内容时——比如我们的新闻提要上的帖子或我们数据档案中列出的广告商——它可能会使用相同的 HTML 标签和 CSS 类模式来显示每条信息。 为了收集包含在这些 HTML 标签中的数据,我们必须识别和理解这些模式。
将信息构建为数据
在本例中,所有广告都在一个整体 `` 标签内,该标签具有类属性 _4t5n 和角色属性 main。 清单 4-1 包含 HTML 代码,用于显示可能存储在存档中的示例 Facebook 广告。
<div class="_4t5n" role="main">
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">Ad name 1</div>
<div class="_3-94 _2lem">Jul 01, 2019 1:45am</div>
</div>
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">Ad name 2</div>
<div class="_3-94 _2lem">Jul 10, 2019 5:25pm</div>
</div>
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">Ad name 3</div>
<div class="_3-94 _2lem">Jul 11, 2019 5:25pm</div>
</div>
--snip--
</div>
清单 4-1:Facebook 广告的示例代码
清单 4-1 包含一个 HTML 标签,其中包含类 _3-96 和 _2let(注意,一对引号内的每个类都用空格分隔)。 这个 标签包含用户点击的 Facebook 广告的标题。 第二个具有 _3-94 和 _2lem 类的 标记包含指示用户何时点击广告的时间戳。
如果我们基于此 HTML 创建了一个电子表格,它可能如图 4-3 所示。
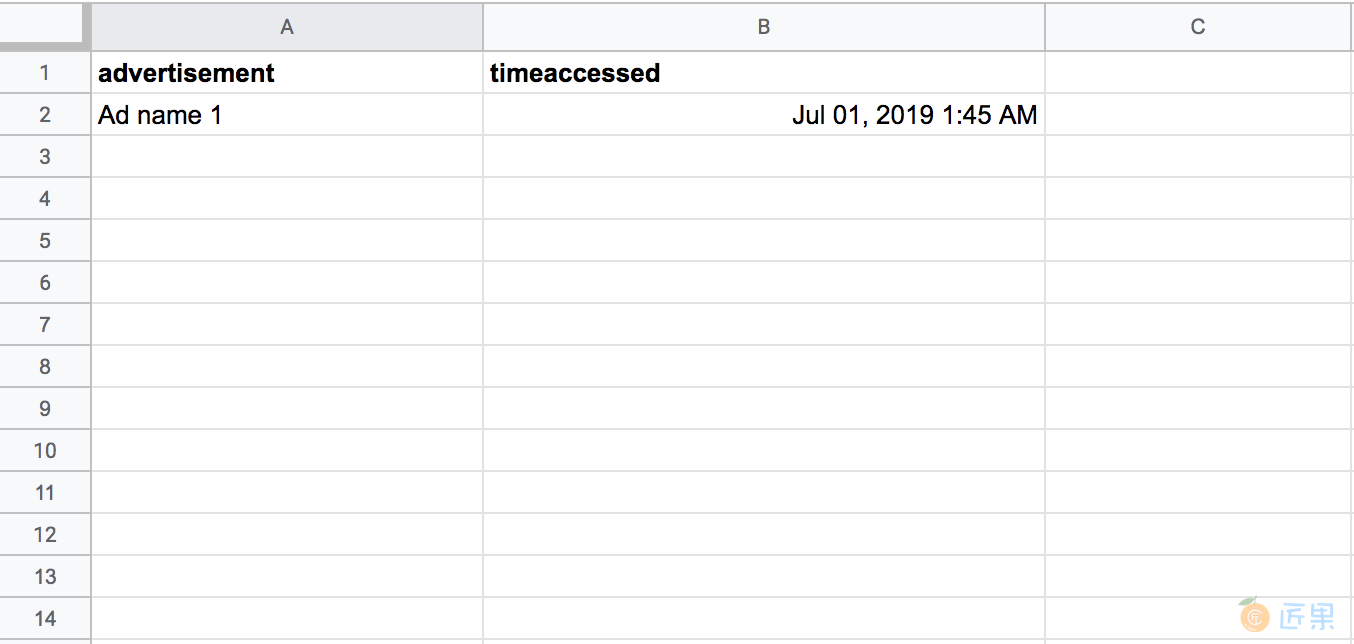
我们使用了两个标题,广告和时间访问,对数据进行分类和结构化。请注意,有很多方法可以做到这一点;我们可以选择只查看广告的标题,或者将时间戳分成 date 和 time_of_day 列。数据收集是一个创造性的过程,您找到的解决方案始终取决于您正在使用的特定项目和数据。
在图 4-3 中,我们通过直接从网页上手动复制数据开始创建电子表格。尽管您可以像这样抓取网页,但正如您想象的那样,这将花费大量时间和精力。几乎所有的网页抓取都是自动完成的。因此,在下一节中,我们将使用 Python 来设置自动抓取工具。
自动抓取
与脚本一样,您可以将刮板视为一个小机器人,它将为您执行重复性任务。就像我们在第 3 章中使用的脚本一样,刮板抓取数据并将其放入电子表格中——除了它从 HTML 页面而不是从 API 响应获取数据。
与 JSON 不同,HTML 数据可能很难处理,因为它并不总是以数据友好的方式构建。然后,制定计划将帮助我们确定网站的哪些部分最适合作为数据进行结构化。正如我们对 API 脚本所做的那样,让我们首先将我们的任务列表写成伪代码,让每个任务成为一个单独的注释,如清单 4-2 所示。
# import libraries
# open our page
# grab all the information for the ads
# put all the ad data into an list
# create a csv file
# write each line into a csv file
清单 4-2:我们的脚本计划
接下来我们将导入我们需要的库,如清单 4-3 所示。
# import libraries
import csv
from bs4 import BeautifulSoup
清单 4-3:导入我们的库
对于这个脚本,我们需要两个库:Python 内置的 CSV 和 Beautiful Soup,一个独立开发人员编写供其他 Python 开发人员使用的库。 Beautiful Soup 允许我们的爬虫阅读和理解 HTML 和 CSS。
因为它没有内置在 Python 中,所以我们需要在使用它之前单独安装 Beautiful Soup。我们在第一章中介绍了库的安装过程。在这种情况下,您可以使用pip命令pip install beautifulsoup4来安装库(beautifulsoup4指的是Beautiful Soup的第四版,它是库的最新和改进最多的版本)。安装任何库后,了解和使用它的最佳方法是查找其文档。您可以在 https://www.crummy.com/software/BeautifulSoup/bs4/doc/ 上找到有关 Beautiful Soup 的文档。
既然已经安装并导入了 Beautiful Soup,我们就可以使用它了。通常情况下,Python 不理解标签是什么,所以当它打开一个 HTML 页面时,信息只是一长串字符和空格,如下所示:
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">See how Facebook is changing</div>
<div class="_3-94 _2lem">Jul 01, 2018 1:45am</div>
</div>
Beautiful Soup 接受 HTML 和 CSS 代码,提取有用的数据,并将其转换为 Python 可以处理的对象——这个过程称为解析。 把 Beautiful Soup 想象成 X 射线护目镜,它让我们的爬虫能够看透 HTML 编码语言并专注于我们真正感兴趣的内容(在以下代码中加粗):
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">See how Facebook is changing</div>
<div class="_3-94 _2lem">Jul 01, 2018 1:45am</div>
</div>
我们将使用 Beautiful Soup 将 HTML 代码转换为一个列表,其中包含每个广告的名称和访问时间。 不过,首先,在包含存档的同一文件夹中创建一个文件并将其保存为 ad_scraper.py,然后在 ad_scraper.py 中设置代码的基本结构,如清单 4-4 所示。
import csv
from bs4 import BeautifulSoup
# make an empty array for your data
① rows = []
# set foldername
② foldername = "facebook-lamthuyvo"
# open messages
with open("%s/ads/advertisers_you've_interacted_with.html" % ③foldername) as ④page:
soup = ⑤BeautifulSoup(page, "html.parser")
示例 4-4:创建一个空列表并打开我们的文件
首先,我们创建行①变量,我们最终将用我们的数据填充它。然后我们创建文件夹名称变量②来保存我们的数据当前所在文件夹的名称,如果我们想抓取别人的存档③,这允许我们在将来轻松修改我们的脚本。然后我们打开 HTML 文件并将其信息存储在页面变量④中。最后,我们将页面传递给 BeautifulSoup() 函数 ⑤。该函数将 HTML 解析为我们可以使用的元素列表;具体来说,它将页面转换为 Beautiful Soup 对象,以便库可以区分 HTML 和其他内容。我们传递给 BeautifulSoup() 的第二个参数“html.parser”告诉 Beautiful Soup 将页面处理为 HTML。
分析 HTML 代码以识别模式
在本章前面,我们看到每个广告名称都包含在具有 _3-96 和 _2let 类的 标签中。与广告相关联的时间戳存储在具有 _3-94 和 _2lem 类的 标记中。
您会在清单 4-1 中注意到其中一些类,例如 _3-96,可能用于其他 标签,例如包含单词 Clicked Ad 的副标题。因为类用于设置可以反复使用的 元素的样式,所以我们需要识别 CSS 类和标签,这些类和标签对于我们要抓取的信息类型是唯一的。也就是说,我们需要能够指示我们的脚本仅从包含我们点击的广告信息的 标签中获取内容。如果我们告诉我们的脚本从 标签中获取信息而不指定类,我们最终会得到很多无关信息,因为 标签用于整个页面的多种内容类型。
获取您需要的元素
为了获得我们想要的内容,首先我们需要添加一些代码来选择包含我们想要获取的所有广告名称和时间戳的父(外部)标签。然后我们将进入父标签并逐个搜索每个`` 标签,以收集我们点击的每个广告的相关信息。
清单 4-5 显示了完成此操作的脚本。
import csv
from bs4 import BeautifulSoup
--snip--
soup = BeautifulSoup(page, "html.parser")
# only grab the content that is relevant to us on the page using the class named "contents"
contents = soup.find("div", ①class_="_4t5n")
# isolate all the lists of ads
② ad_list = contents.find_all( "div" , class_="uiBoxWhite")
示例 4-5:使用 Beautiful Soup 选择特定的
首先,我们寻找一个带有 _4t5n ① 类的 标签,我们从清单 4-1 中知道它将包含所有带有我们想要抓取的广告信息的 标签。我们通过将 find() 函数应用于soup 来查找这个标签,这是我们之前在代码中解析的HTML。然后我们将(使用等号)将此函数的结果分配给变量内容。
要查找具有特定类的 标记,find() 函数需要两个参数。首先,它需要知道它在寻找哪种 HTML 标签。在这种情况下,我们正在寻找 `` 标签,我们通过字符串“div”指定它(确保在单词 div 周围保留引号)。
但是如果我们使用soup.find("div") 运行仅带有“div”参数的代码,我们的脚本将不会为我们返回正确的标签。相反,我们的爬虫会遍历整个 HTML 文件,找到每个 标签,然后只渲染它找到的最后一个。
注意 find() 函数旨在遍历整个代码,识别它在存储在soup 变量中的代码中找到的每个标记,直到它结束为止。因此,因为 find() 旨在只查找一个 标签,所以它只保留最后一个——而不是它循环遍历的所有其他标签。
为了不仅查找任何 标签,而且查找具有 _4t5n 类的标签,我们需要将第二个参数 class_="_4t5n" ① 传递到 find() 函数中。指定 标签使用的类有助于我们只获取我们感兴趣的 `` 标签。
一旦我们有一个包含所有存储在内容中的广告 的 ,我们就可以浏览内容,选择每个包含广告信息的 标签,并将这些 存储在一个列表中。我们可以通过将 find_all() 函数应用于内容类②来实现。我们使用 find_all() 而不是 find() 来返回每个带有 uiBoxWhite 类的 标签。该函数现在应该将结果作为列表返回,我们将其存储在 ad_list 变量中。
提取内容
获得广告列表后,我们需要获取每个广告的标题和时间戳。为此,我们将使用 for 循环遍历 ad_list 中的每个 标记并提取其内容。清单 4-6 显示了如何在 Python 中执行此操作。
--snip--
ad_list = contents.find_all("div", class_="uiBoxWhite")
① for item in ad_list:
② advert = item.find("div", class_="_2let").get_text()
③ timeaccessed = item.find("div", class_="_2lem").get_text()
示例 4-6:提取 HTML `` 标签的内容
首先,我们编写一个语句来介绍 for 循环①。 ad_list: 中的 item 行表示我们将逐项遍历列表,将当前项存储在 item 变量中,然后运行我们在 for 循环后面的行中指定的过程。 在这种情况下, item 包含一个带有 uiBoxWhite 类的 标记。
然后我们将从 item 中获取一个类为 _2let 的 `` 标签,并将其存储在 advert 变量②中。 但是请注意,我们不只是使用 find(); 我们还通过在行尾调用 get_text() 将另一个函数链接到 find() 上。 Python 和 Beautiful Soup 等库允许您通过在一个函数的末尾调用另一个函数来修改该函数的结果,这个过程称为链接。 在这种情况下, find() 函数允许我们获取一个 ,它可能如下所示:
<div class="_3-96 _2let">See how Facebook is changing</div>
然后我们应用 get_text() 函数来获取 `` 标签中包含的文本:
看看 Facebook 是如何变化的
我们重复这个过程,从使用 _2lem 类 ③ 的 `` 标签中提取时间戳信息。
哇,我们刚刚让我们的刮刀做了大量的工作! 让我们重新审视我们的 HTML 代码,以便我们知道抓取工具刚刚解析了哪些信息:
① <div class="_4t5n" role="main">
② <div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
③ <div class="_3-96 _2let">See how Facebook is changing</div>
④ <div class="_3-94 _2lem">Jul 01, 2018 1:45am</div>
</div>
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">Ad name 2</div>
<div class="_3-94 _2lem">Jul 10, 2018 5:25pm</div>
</div>
<div class="pam _3-95 _2pi0 _2lej uiBoxWhite noborder">
<div class="_3-96 _2pio _2lek _2lel">Clicked Ad</div>
<div class="_3-96 _2let">Ad name 3</div>
<div class="_3-94 _2lem">Jul 11, 2018 5:25pm</div>
</div>
--snip--
</div>
回顾一下:我们的抓取工具首先找到包含所有广告 ① 的 标签,将每个广告变成一个列表项 ②,然后遍历每个广告,从每个嵌套的 标签中提取其标题 ③ 和时间戳 ④。
将数据写入电子表格
现在我们知道如何使用我们的爬虫来获取我们需要的信息。 但是我们还没有告诉我们的小机器人如何处理这些信息。 这就是 .csv 文件可以提供帮助的地方——是时候告诉我们的抓取工具将它正在读取的数据转换成我们人类可以读取的电子表格了。
建立你的行列表
我们需要指示我们的脚本将每一行数据写入电子表格,就像我们在编写 API 时所做的那样。 但这一次我们将通过创建一个 Python 字典来实现,这是一种允许我们将特定数据点(值)分配给特定数据类别(键)的数据结构。 字典类似于 JSON,因为它将值映射到键。
以最简单的形式,字典如下所示:
row = {
"key_1": "value_1",
"key_2": "value_2"
}
在本例中,我使用一对大括号 ({}) 定义了一个名为 row 的变量。字典中的数据在这些大括号内(请注意,我添加了一些换行符和空格以使字典更清晰)。
在字典中,我们的值存储在键和值对中。在这种情况下,有两个键,“key_1”和“key_2”,每个键都与一个值“value_2”和“value_2”配对。每个键值对由逗号分隔,使其成为两个不同对的列表。将键想象成电子表格中的列标题。在此示例中,字符串 key_1 将代表列标题,而 value_1 将是该列中的单元格之一。如果这种结构看起来很熟悉,这绝非偶然:这就是 JSON 数据的结构方式。在某些方面,您可以将 Python 词典视为可能以 JSON 格式构建的数据的蓝图。
回到我们的具体示例,让我们为我们的数据创建一个字典并将其附加到我们的 .csv 文件中,如清单 4-7 所示。
--snip--
for item in ad_list:
advert = item.find("div", class_="_2let").get_text()
timeaccessed = item.find("div", class_="_2lem").get_text()
① row = {
② "advert": ③advert,
② "timeaccessed": ③timeaccessed
}
④ rows.append(row)
清单 4-7:将数据写入 .csv 文件
键“advert”和“timeaccessed”②是代表我们想要收集的数据类型的字符串——相当于我们电子表格中的列标题。每个键都与一个变量配对:“advert”键与 advert 变量对应,“timeaccessed”键与 timeaccessed 变量对应 ③。回想一下,我们之前使用这些变量来临时存储我们使用 Beautiful Soup 从每个 HTML 元素中提取的文本。我们将此字典存储在行变量①中。
一旦我们有了我们的行,我们需要将它与其他行一起存储。这是我们在脚本顶部定义的行变量发挥作用的地方。在 for 循环的每次迭代期间,我们使用 append() 函数 ④ 将另一行数据添加到行列表中。这允许我们从每个列表项中获取最新值,将这些值分配给适当的键,并将键和值附加到我们的行变量中。整个过程允许我们在每个循环中积累新的数据行,确保我们提取有关我们点击的每个广告的信息,并使用这些数据填充行列表,以便我们可以将其写入 .csv 文件中下一步。
写入您的 .csv 文件
最后但并非最不重要的是,我们需要打开一个 .csv 文件并将每一行写入其中。如前所述,此过程与您在第 3 章中看到的略有不同。我们将使用 DictWriter(),而不是使用 CSV 库提供的简单 writer() 函数,该函数知道如何处理字典.这应该可以帮助我们避免任何粗心的错误,比如不小心交换了我们的列值。
清单 4-8 显示了创建 .csv 文件的代码。
--snip--
① with open("../output/%s-all-advertisers.csv" % foldername, "w+") as csvfile :
② fieldnames = ["advert", "timeaccessed"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames) ③
writer.writeheader() ④
for row in rows: ⑤
writer.writerow(row)⑥
清单 4-8:将数据转换为 .csv 文件
首先,我们使用字符串 facebook- -all-advertisers.csv 创建并打开一个新文件①(您之前将我的用户名 lamthuyvo 替换为您的用户名,如清单 4-4 所示),它是文件夹名称的串联变量和包含 .csv 文件的文件夹的名称。然后我们打开 .csv 文件并将其称为 csvfile。接下来,我们创建一个名为 fieldnames 的变量来存储字符串列表②,这些字符串对应于我们在清单 4-7 中定义的字典中的键。这很重要,因为我们随后使用 DictWriter() 函数 ③ 指示 Python 根据包含我们在 fieldnames 中指定的键的字典编写数据。 DictWriter() 函数需要参数 fieldnames 来知道我们的 .csv 文件的列标题是什么以及它应该访问我们数据行的哪些部分。换句话说,我们在 fieldnames 变量中列出和存储的字段名称代表我们希望 DictWriter() 函数写入我们的 .csv 文件的数据部分。
然后我们使用 writeheader() 函数 ④ 写入 .csv 文件的第一行,即每列的标题。由于 writer 已经知道上一行中的那些字段名称,我们不需要指定任何内容,我们的 .csv 文件现在应该如下所示:
advert,metadata
剩下的就是添加我们的数据。 通过遍历行 ⑤ 中的每一行,我们可以将每一行数据写入我们的电子表格⑥。
最后,一旦我们将所有部分拼接在一起,我们的脚本应该如清单 4-9 所示。
import csv
from bs4 import BeautifulSoup
rows = []
foldername = "facebook-lamthuyvo"
with open("%s/ads/advertisers_you've_interacted_with.html" % foldername) as page:
soup = BeautifulSoup(page, "html.parser")
contents = soup.find("div", class_="_4t5n")
ad_list = contents.find_all( "div" , class_="uiBoxWhite")
for item in ad_list:
advert = item.find("div", class_="_2let").get_text()
metadata = item.find("div", class_="_2lem").get_text()
row = { "advert": advert,
"metadata": metadata
}
rows.append(row)
with open("%s-all-advertisers.csv" % foldername, "w+") as csvfile:
fieldnames = ["advert", "metadata"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in rows:
writer.writerow(row)
清单 4-9:完整的爬虫脚本
看起来挺好的! 让我们试一试。
运行脚本
在本章开头,您将文件保存为名为 ad_scraper.py 的脚本,保存在包含 Facebook 存档的同一文件夹中。 现在您可以像运行任何其他 Python 脚本一样运行它。 在控制台中,导航到该特定文件夹。 对于 Mac 用户,运行以下命令:
python3 ad_scraper.py
在 Windows 机器上,改为运行以下代码:
python ad_scraper.py
运行脚本后,您的抓取工具应该会检查您在过去三个月内点击过的每个广告,并且您应该会看到一个名称以 -all-advertisers.csv 结尾的文件。此文件应包含存档页面 adsrs_you've_interacted_with.html 中列出的每个广告的标题和时间戳。这些数据将帮助您更好地了解您在 Facebook 上的行为;例如,您可以使用它来了解您在哪几天或哪几个月点击了大量广告。或者,您可以查看多次点击的广告。
本章中的示例代表了一个非常简单的网络抓取版本:我们抓取的 HTML 页面是我们可以下载的(不是我们必须通过连接到互联网才能打开的),我们从页面抓取的数据量不是大的。
抓取像我们档案中的那些简单的 HTML 页面是对网页抓取基本原理的很好的介绍。希望本练习将帮助您过渡到更复杂的抓取网站——无论是在线托管且经常更改的网页,还是具有更复杂结构的 HTML 页面。
概括
在本章中,您学习了如何检查 Facebook 档案中的 HTML 页面以查找代码中的模式,这些模式允许您将在页面上看到的内容构建为数据。您学习了如何使用 Beautiful Soup 库读取 HTML 页面,识别并获取包含您要收集的信息的 `` 标签,使用字典将该信息存储在数据行中,最后编写该字典使用 DictWriter() 函数转换为 .csv 文件。但更重要的是,您学会了如何从网页中提取信息并将其写入数据文件,您可以将其输入各种分析工具(如 Google 表格)或 Python 渲染网络应用程序(如 Jupyter Notebook)——我们将看到这两种工具在后面的章节中。这意味着我们现在已经获取了锁定在网页中的信息并将其转换为更易于分析的格式!
在下一章中,我们将在您在这里学到的知识的基础上,通过应用类似的过程来抓取一个在互联网上运行的网站。