树就是树,你还需要考虑些什么呢? -- 罗纳德·里根
设想你正在为一个著名的科技新闻网站开发新版本。
这是一个很前卫的网站,因此,读者可以评论原文甚至相互回复,这样就某一主题的讨论又延伸出很多新的分支,其深度就会大大增加。你选择了一个简单的解决方案来跟踪这些回复分支:每条评论引用它所回复的评论。
Trees/intro/parent.sql
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
parent_id BIGINT UNSIGNED,
comment TEXT NOT NULL,
FOREIGN KEY (parent_id) REFERENCES Comments(comment_id)
);
很快,程序的逻辑就变得清晰起来,然而,要用一条简单的SQL语句检索一个很长的回复分支,还是很困难的。你只能获取一条评论的下一级或者联结第二级,到一个固定的深度。但这个贴子可以是无限深的,你可能需要执行很多次SQL查询才能获取给定主题的所有评论。
另一个你想到的主意是先获取一个主题的所有评论,然后再在程序的栈内存中将这些数据整合成你在学校里学到的传统的树形数据结构。但是,网站的产品人员告诉你,他们每天会发布数十篇文章,每篇文章可能有几百上千条评论,因此当每次有人访问网站都要做一次数据重整是不切实际的。
一定有一个更好的方法来存储评论的分支,同时可以简单而高效地获取一个完整的评论分支。
3.1 目标:分层存储与查询
存在递归关系的数据很常见,数据常会像树或者以层级方式组织。在树形结构中,实例被称为节点(node)。每个节点有多个子节点和一个父节点。最上层的节点叫根(root)节点,它没有父节点。最底层的没有子节点的节点叫叶(leaf)。而中间的节点简单地称为非叶(nonleaf)节点。
在层级数据中,你可能需要查询与整个集合或其子集相关的特定对象,例如下述树形数据结构。
- 组织架构图。职员与经理的关系是典型的树形结构数据,出现在无数的SQL书籍与论题中。在组织架构图中,每个职员有一个经理,在树结构中表现为职员的父节点。同时,经理也是一个职员。
- 话题型讨论。正如引言中介绍的,树形结构也能用来表示回复评论的评论链。在这种树中,评论的子节点是它的回复。
本章将用话题型讨论作为案例来讨论反模式及其解决方案。
3.2 反模式:总是依赖父节点
在很多书籍或文章中,最常见的简单解决方案是添加parent_id字段,引用同一张表中的其他回复。可以建一个外键约束来维护这种关系。下面是表的定义,图3-1是实例关系图。
Trees/anti/adjacency-list.sql
CREATE TABLE Comments(
comment_id SERIAL PRIMARY KEY,
parent_id BIGINT UNSIGNED,
bug_id BIGINT UNSIGNED NOT NULL,
author BIGINT UNSIGNED NOT NULL,
comment_date DATETIME NOT NULL,
comment TEXT NOT NULL,
FOREIGN KEY (parent_id) REFERENCES Comments(comment_id),
FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id),
FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
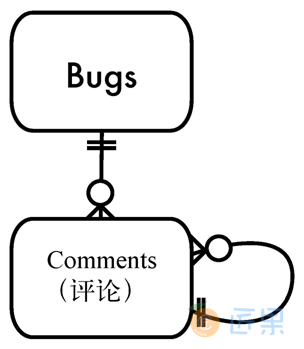
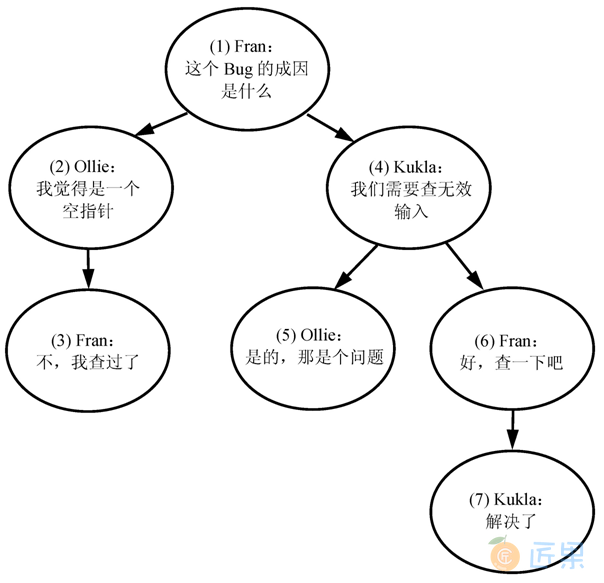
这样的设计叫做邻接表。这可能是程序员们用来存储分层结构数据中最普通的方案了。下表展示了一些简单的范例数据来显示评论表中的分层结构数据,同时图3-2展示了一棵该结构的树。
| comment_id | parent_id | author | comment |
|---|---|---|---|
| 1 | NULL | Fran | 这个Bug的成因是什么 |
| 2 | 1 | Ollie | 我觉得是一个空指针 |
| 3 | 2 | Fran | 不,我查过了 |
| 4 | 1 | Kukla | 我们需要查无效输入 |
| 5 | 4 | Ollie | 是的,那是个问题 |
| 6 | 4 | Fran | 好,查一下吧 |
| 7 | 6 | Kukla | 解决了 |
3.2.1 使用邻接表查询树
但是,就算如此多的程序员会将邻接表作为默认的解决方案,它仍然可能成为一个反模式,原因在于它无法完成树操作中最普通的一项:查询一个节点的所有后代。你可以使用一个关联查询来获取一条评论和它的直接后代:
Trees/anti/parent.sql
SELECT c1.*, c2.* FROM Comments c1 LEFT OUTER JOIN Comments c2
ON c2.parent_id = c1.comment_id;
然而,这个查询只能获取两层的数据。树的特性就是它可以任意深地扩展,因而你需要有方法来获取任意深度的数据。比如,可能需要计算一个评论分支的数量,或者计算一个机械设备所有部分的总开销。
当你使用邻接表的时候,这样的查询会变得很不优雅,因为每增加一层的查询都会需要额外扩展一个联结,而SQL查询中联结的次数是有上限的。如下的查询能够获得四层数据,但无法更多了:
Trees/anti/ancestors.sql
SELECT c1.*, c2.*, c3.*, c4.* FROM Comments c1 -- 1st level
LEFT OUTER JOIN Comments c2
ON c2.parent_id = c1.comment_id -- 2nd level
LEFT OUTER JOIN Comments c3
ON c3.parent_id = c2.comment_id -- 3rd level
LEFT OUTER JOIN Comments c4
ON c4.parent_id = c3.comment_id; -- 4th level
这样的查询很笨拙,因为伴随着逐渐增加的后代层次,必须同等地增加联结查询的列。这使得执行一个聚合函数(比如COUNT())变得极其困难。
另一种通过邻接表来获取树结构数据的方法是,先查询出所有行,在应用程序中自顶向下地重新构造出这棵树,然后再像树一样使用这些数据。
Trees/anti/all-comments.sql
SELECT * FROM Comments WHERE bug_id = 1234;
在处理数据之前就进行从数据库到应用程序之间的大量数据复制,是非常低效的,你可能仅仅需要一棵子树,而不是从根开始的完整的树;或者可能仅仅需要这些数据的聚合信息,比如评论的总数量(使用COUNT()函数)。
3.2.2 使用邻接表维护树
无可否认,一些操作通过邻接表来实现是非常方便的,比如增加一个叶子节点:
Trees/anti/insert.sql
INSERT INTO Comments (bug_id, parent_id, author, comment)
VALUES (1234, 7, 'Kukla', 'Thanks!');
修改一个节点的位置或者一棵子树的位置也是很简单的:
Trees/anti/update.sql
UPDATE Comments SET parent_id = 3 WHERE
comment_id = 6;
然而,从一棵树中删除一个节点会变得比较复杂。如果需要删除一棵子树,你不得不执行多次查询来找到所有的后代节点,然后逐个从最低级别开始删除这些节点以满足外键完整性。
Trees/anti/delete-subtree.sql
SELECT comment_id FROM Comments WHERE parent_id = 4; -- returns 5 and 6
SELECT comment_id FROM Comments WHERE parent_id = 5; -- returns none
SELECT comment_id FROM Comments WHERE parent_id = 6; -- returns 7
SELECT comment_id FROM Comments WHERE parent_id = 7; -- returns none
DELETE FROM Comments WHERE comment_id IN ( 7 );
DELETE FROM Comments WHERE comment_id IN ( 5, 6 );
DELETE FROM Comments WHERE comment_id = 4;
可以使用一个带ON DELETE CASCADE修饰符的外键约束来自动完成这些操作,只要能肯定确实是要删除这些节点,而不是修改它们的位置。
假如想要删除一个非叶子节点并且提升它的子节点,或者将它的子节点移动到另一个节点下,那么首先要修改子节点的parent_id,然后才能删除那个节点。
Trees/anti/delete-non-leaf.sql
SELECT parent_id FROM Comments WHERE comment_id = 6; -- returns 4
UPDATE Comments SET parent_id = 4 WHERE parent_id = 6;
DELETE FROM Comments WHERE comment_id = 6;
这些都是使用邻接表时需要多步操作才能完成的查询范例,你不得不写很多额外的代码,而其实数据库设计本身就能做得很简单和高效。
3.3 如何识别反模式
如果听到了如下的问题,可能你正在使用“单纯的树”这种反模式。
- “我们的树结构要支持多少层?”你正纠结于不使用递归查询获取一个给定节点的所有祖先或者后代。你做出让步,只支持有限层级数据的所有的操作,然后紧接着的一个很自然的问题就是:多少层才足够满足需求?
- “我总是很怕接触那些管理树结构的代码。”你已经采用了一种管理分层数据的比较复杂的方法,但使用的是错误的方法。每一项技术都会使得一些任务变得很简单,但通常是以其他的任务变得更复杂作为代价的。你可能选择了在应用程序设计中并不是最佳的方案来管理这些分层数据。
- “我需要一个脚本来定期地清理树中的孤立节点数据。”你的应用程序因为删除了非叶子节点而产生了一些迷失节点。在数据库中存储了一些复杂的结构时,需要确保在任何改变之后,这个结构都处在一致的、有效的状态下。你可以使用本章后面所描述的任何解决方案,同时配合触发器、级联外键等,来使得数据存储的结构更加适合项目需求,尽可能少地产生零碎的数据。
3.4 合理使用反模式
某些情况下,在应用程序中使用邻接表设计可能正好适用。邻接表设计的优势在于能快速地获取一个给定节点的直接父子节点,它也很容易插入新节点。如果这样的需求就是你的应用程序对于分层数据的全部操作,那使用邻接表就可以很好地工作了。
不要过度设计
我曾经为一个计算机数据中心写过一个库存跟踪程序。一些器材安装在电脑主机内部。比如缓存磁盘控制器是装在一个机架服务器里面的,扩展内存模块是装在磁盘控制器上的,等等。
我需要一个简单的数据库解决方案,来追踪那些包含了其他小部件的大设备的使用情况,同时也需要追踪每个独立部件的情况,并给出关于设备使用情况、折旧状态以及投资收益率的报表。
项目经理认为大的部件包含了一系列其他部件,同时这些部件还能再包含更小的部件,因而数据结构上这种层级关系可以是任意深度的。最终那花了我几个星期的时间来调整代码,以便让这棵树很好地适应数据库、用户界面、管理员界面和最终生成的报表。
然而在实际生产过程中,这个库存系统从来不曾有哪些设备间的关系达到两层嵌套,都是简单的父—子关系而已。如果我的最终用户能在一开始就确认两层的关系足够满足产品的需求,那么我们可以减少很大一部分的工作量。
某些品牌的数据库管理系统提供扩展的SQL语句,来支持在邻接表中存储分层数据结构。SQL-99标准定义了递归查询的表达式规范,使用WITH关键字加上公共表表达式。
Trees/legit/cte.sql
WITH CommentTree
(comment_id, bug_id, parent_id, author, comment, depth) AS (
SELECT *, 0 AS depth FROM Comments
WHERE parent_id IS NULL
UNION ALL
SELECT c.*, ct.depth+1 AS depth FROM CommentTree ct
JOIN Comments c ON (ct.comment_id = c.parent_id)
) SELECT * FROM CommentTree WHERE bug_id = 1234;
Microsoft SQL Server 2005、Oracle 11_g_、IBM DB2和PostgreSQL 8.4都支持使用如上的查询表达式来进行递归查询。
和Oracle 10_g_一样,MySQL、SQLite和Infomix是少数几个暂时还不支持这种表达式的数据库,它们都被广泛地应用。也许我们可以假设将来递归查询语法将被所有的主流数据库所支持,那么使用邻接表的设计也不会再受到这么多限制了。
Oracle 9_i_和10_g_也支持WITH子句,但并不是在递归查询时使用的。它们有着自己特殊的语法定义:START WITH和CONNECT BY PRIOR。
Trees/legit/connect-by.sql
SELECT * FROM Comments START WITH comment_id = 9876 CONNECT BY PRIOR parent_id = comment_id;
3.5 解决方案:使用其他树模型
有几种方案可以代替邻接表模型,包括路径枚举、 嵌套集以及闭包表。接下来我将分三段来展示这三种设计方案是如何解决3.2节中所描述的存储和查询树型评论的问题的。
这些解决方案通常是这样的:首先可能看上去比邻接表复杂很多,但它们的确使得某些使用邻接表比较复杂或者很低效的操作变得更简单。如果你的应用程序确实需要提供这些操作,那么这些设计会是比邻接表更好的选择。
3.5.1 路径枚举
邻接表的缺点之一是从树中获取一个给定节点的所有祖先的开销很大。路径枚举的设计通过将所有祖先的信息联合成一个字符串,并保存为每个节点的一个属性,很巧妙地解决了这个问题。
路径枚举是一个由连续的直接层级关系组成的完整路径。如/usr/local/lib的UNIX路径是文件系统的一个路径枚举,其中usr是local的父亲,这也就意味着usr是lib的祖先。
在Comments表中,我们使用类型为VARCHAR的path字段来代替原来的parent_id字段。这个path字段所存储的内容为当前节点的最顶层的祖先到它自己的序列,就像UNIX的路径一样,你甚至可以使用‘/’作为路径中的分割符。
Trees/soln/path-enum/create-table.sql
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
path VARCHAR(1000),
bug_id BIGINT UNSIGNED NOT NULL,
author BIGINT UNSIGNED NOT NULL,
comment_date DATETIME NOT NULL,
comment TEXT NOT NULL,
FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id),
FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
| comment_id | path | author | comment |
|---|---|---|---|
| 1 | 1/ | Fran | 这个Bug的成因是什么 |
| 2 | 1/2/ | Ollie | 我觉得是一个空指针 |
| 3 | 1/2/3/ | Fran | 不,我查过了 |
| 4 | 1/4/ | Kukla | 我们需要查无效输入 |
| 5 | 1/4/5/ | Ollie | 是的,那是个问题 |
| 6 | 1/4/6/ | Fran | 好,查一下吧 |
| 7 | 1/4/6/7/ | Kukla | 解决了 |
你可以通过比较每个节点的路径来查询一个节点的祖先。比如,要找到评论#7——路径是1/4/6/7——的祖先,可以这样做:
Trees/soln/path-enum/ancestors.sql
SELECT * FROM Comments AS c WHERE '1/4/6/7/' LIKE c.path || '%';
这句查询语句会匹配到路径为1/4/6/%、1/4/%以及1/%的节点,而这些节点就是评论#7的祖先。
同时还可以通过将LIKE关键字两边的参数互换,来查询一个给定节点的所有后代。比如查找评论#4——路径为1/4——的所有后代,可以使用如下的语句:
Trees/soln/path-enum/descendants.sql
SELECT * FROM Comments AS c WHERE c.path LIKE '1/4/' || '%';
这句查询语句所找到的后代的路径分别是1/4/5、1/4/6以及1/4/6/7。
一旦你可以很简单地获取一棵子树或者从子孙节点到祖先节点的路径,就可以很简单地实现更多的查询,比如计算一棵子树所有节点上的值的总和(使用SUM聚合函数),或者仅仅是单纯地计算节点的数量。如果要计算从评论#4扩展出的所有评论中每个用户的评论数量,可以这样做:
Trees/soln/path-enum/count.sql
SELECT COUNT(*) FROM Comments AS c WHERE c.path LIKE '1/4/' || '%' GROUP BY c.author;
插入一个节点也可以像使用邻接表一样地简单。可以插入一个叶子节点而不用修改任何其他的行。你所需要做的只是复制一份要插入节点的逻辑上的父亲节点的路径,并将这个新节点的ID追加到路径末尾就行了。如果这个ID是在插入时自动生成的,你可能需要先插入这条记录,然后获取这条记录的ID,并更新它的路径。比如,你使用的是MySQL,它的内置函数LAST_INSERT_ID()会返回当前会话的最新一条插入记录的ID,通过调用这个函数,便可以获得你所需要的ID,然后就可以通过新节点的父亲节点来获取完整的路径了。
Trees/soln/path-enum/insert.sql
INSERT INTO Comments (author, comment) VALUES ('Ollie', 'Good job!');
UPDATE Comments SET path = (SELECT path FROM Comments WHERE comment_id = 7)
|| LAST_INSERT_ID() || '/'
WHERE comment_id = LAST_INSERT_ID();
路径枚举的方案也存在这一些缺点,比如就存在第2章“乱穿马路”中所描述的缺点:数据库不能确保路径的格式总是正确或者路径中的节点确实存在。依赖于应用程序的逻辑代码来维护路径的字符串,并且验证字符串的正确性的开销很大。无论将VARCHAR的长度设定为多大,依旧存在长度限制,因而并不能够支持树结构的无限扩展。
路径枚举的设计方式能够很方便地根据节点的层级排序,因为路径中分隔符两边的节点间的距离永远是1,因此通过比较字符串长度就能知道层级的深浅。
3.5.2 嵌套集
嵌套集解决方案是存储子孙节点的相关信息,而不是节点的直接祖先。我们使用两个数字来编码每个节点,从而表示这一信息,可以将这两个数字称为nsleft和nsright。
Trees/soln/nested-sets/create-table.sql
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
nsleft INTEGER NOT NULL,
nsright INTEGER NOT NULL,
bug_id BIGINT UNSIGNED NOT NULL,
author BIGINT UNSIGNED NOT NULL,
comment_date DATETIME NOT NULL,
comment TEXT NOT NULL,
FOREIGN KEY (bug_id) REFERENCES Bugs (bug_id),
FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
每个节点通过如下的方式确定nsleft和nsright的值:nsleft的数值小于该节点所有后代的ID,同时nsright的值大于该节点所有后代的ID。这些数字和comment_id的值并没有任何关联。
确定这三个值(nsleft,comment_id,nsrigh)的简单方法是对树进行一次深度优先遍历,在逐层深入的过程中依次递增地分配nsleft的值,并在返回时依次递增地分配nsright的值。
通过图3-3可以简单地想象出这样的分配方式。
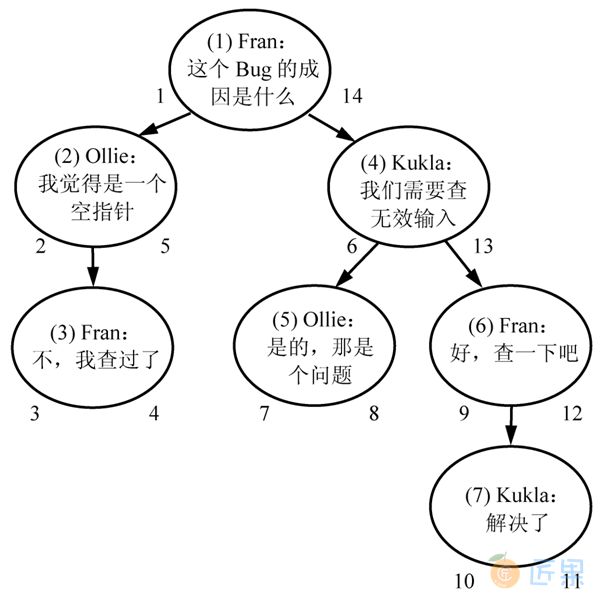
| comment_id | nsleft | nsright | author | comment |
|---|---|---|---|---|
| 1 | 1 | 14 | Fran | 这个Bug的成因是什么 |
| 2 | 2 | 5 | Ollie | 我觉得是一个空指针 |
| 3 | 3 | 4 | Fran | 不,我查过了 |
| 4 | 6 | 13 | Kukla | 我们需要查无效输入 |
| 5 | 7 | 8 | Ollie | 是的,那是个问题 |
| 6 | 9 | 12 | Fran | 好,查一下吧 |
| 7 | 10 | 11 | Kukla | 解决了 |
一旦你为每个节点分配了这些数字,就可以使用它们来找到给定节点的祖先和后代。比如,可以通过搜索哪些节点的ID在评论#4的nsleft和nsright范围之间来获取评论#4及其所有后代。
Trees/soln/nested-sets/descendants.sql
SELECT c2.* FROM Comments AS c1
JOIN Comments as c2
ON c2.nsleft BETWEEN c1.nsleft AND c1.nsright WHERE c1.comment_id = 4;
通过搜索评论#6的ID在哪些节点的nsleft和nsright范围之内,可以获取评论#6及其所有祖先:
Trees/soln/nested-sets/ancestors.sql
SELECT c2.* FROM Comments AS c1
JOIN Comment AS c2
ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright WHERE c1.comment_id = 6;
使用嵌套集设计的主要优势便是,当你想要删除一个非叶子节点时,它的后代会自动地代替被删除的节点,成为其直接祖先节点的直接后代。尽管每个节点的左右两个值在示例图中是有序分配,而每个节点也总是和它相邻的父兄节点进行比较,但嵌套集设计并不必须保存分层关系。因而当删除一个节点造成数值不连续时,并不会对树的结构产生任何影响。
比如,你可以计算给定节点的深度然后删除它的父亲节点,随后,当你再次计算这个节点的深度的时候,它已经自动减少了一层。
Trees/soln/nested-sets/depth.sql
-- Reports depth = 3
SELECT c1.comment_id, COUNT(c2.comment_id) AS depth FROM Comment AS c1
JOIN Comment AS c2
ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright WHERE c1.comment_id = 7
GROUP BY c1.comment_id;
DELETE FROM Comment WHERE comment_id = 6; -- Reports depth = 2
SELECT c1.comment_id, COUNT(c2.comment_id) AS depth FROM Comment AS c1
JOIN Comment AS c2
ON c1.nsleft BETWEEN c2.nsleft AND c2.nsright
WHERE c1.comment_id = 7
GROUP BY c1.comment_id;
然而,某些在邻接表的设计中表现得很简单的查询,比如获取一个节点的直接父亲或者直接后代,在嵌套集的设计中会变得比较复杂。在嵌套集中,如果需要查询一个节点的直接父亲,我们会这么做:给定节点c1的直接父亲是这个节点的一个祖先,且这两个节点之间不应该有任何其他的节点,因此,你可以用一个递归的外联结来查询一个节点x,它即是c1的祖先,也同时是另一个Y节点的后代,随后我们使Y=x并继续查询,直到查询返回空,即不存在这样的节点,此时的Y便是c1的直接父亲节点。
比如,要找到评论#6的直接父亲,你可以这样做:
Trees/soln/nested-sets/parent.sql
SELECT parent.* FROM Comment AS c
JOIN Comment AS parent
ON c.nsleft BETWEEN parent.nsleft AND parent.nsright
LEFT OUTER JOIN Comment AS in_between
ON c.nsleft BETWEEN in_between.nsleft AND in_between.nsright AND in_between.nsleft BETWEEN parent.nsleft AND parent.nsright
WHERE c.comment_id = 6
AND in_between.comment_id IS NULL;
对树进行操作,比如插入和移动节点,使用嵌套集会比其他的设计复杂很多。当插入一个新节点时,你需要重新计算新插入节点的相邻兄弟节点、祖先节点和它祖先节点的兄弟,来确保它们的左右值都比这个新节点的左值大。同时,如果这个新节点是一个非叶子节点,你还要检查它的子孙节点。假设新插入的节点是一个叶子节点,如下的语句可以更新每个需要更新的地方:
Trees/soln/nested-sets/insert.sql
-- make space for NS values 8 and 9
UPDATE Comment
SET nsleft = CASE WHEN nsleft >= 8 THEN nsleft+2 ELSE nsleft END,
> nsright = nsright+2
WHERE nsright >= 7; -- create new child of comment #5, occupying
> NS values 8 and 9
INSERT INTO Comment (nsleft, nsright, author, comment)
VALUES (8, 9, 'Fran', 'Me too!');
如果简单快速地查询是整个程序中最重要的部分,嵌套集是最佳选择——比操作单独的节
点要方便快捷很多。然而,嵌套集的插入和移动节点是比较复杂的,因为需要重新分配左右值,如果你的应用程序需要频繁的插入、删除节点,那么嵌套集可能并不适合。
3.5.3 闭包表
闭包表是解决分级存储的一个简单而优雅的解决方案,它记录了树中所有节点间的关系,而不仅仅只有那些直接的父子关系。
在设计评论系统时,我们额外创建了一张叫做TreePaths的表,它包含两列,每一列都是一个指向Comments中comment_id的外键。
Trees/soln/closure-table/create-table.sql
CREATE TABLE Comments (
comment_id SERIAL PRIMARY KEY,
bug_id BIGINT UNSIGNED NOT NULL,
author BIGINT UNSIGNED NOT NULL,
comment_date DATETIME NOT NULL,
comment TEXT NOT NULL,
FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id),
FOREIGN KEY (author) REFERENCES Accounts(account_id)
);
CREATE TABLE TreePaths (
ancestor BIGINT UNSIGNED NOT NULL,
descendant BIGINT UNSIGNED NOT NULL,
PRIMARY KEY(ancestor, descendant),
FOREIGN KEY (ancestor) REFERENCES Comments(comment_id),
FOREIGN KEY (descendant) REFERENCES Comments(comment_id)
);
我们不再使用Comments表来存储树的结构,而是将树中任何具有祖先—后代关系的节点对都存储在TreePaths表的一行中,即使这两个节点之间不是直接的父子关系;同时,我们还增加一行指向节点自己。更形象的表示可以参考图3-4。
| 祖 先 | 后 代 | 祖 先 | 后 代 | 祖 先 | 后 代 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 7 | 4 | 6 |
| 1 | 2 | 2 | 2 | 4 | 7 |
| 1 | 3 | 2 | 3 | 5 | 5 |
| 1 | 4 | 3 | 3 | 6 | 6 |
| 1 | 5 | 4 | 4 | 6 | 7 |
| 1 | 6 | 4 | 5 | 7 | 7 |
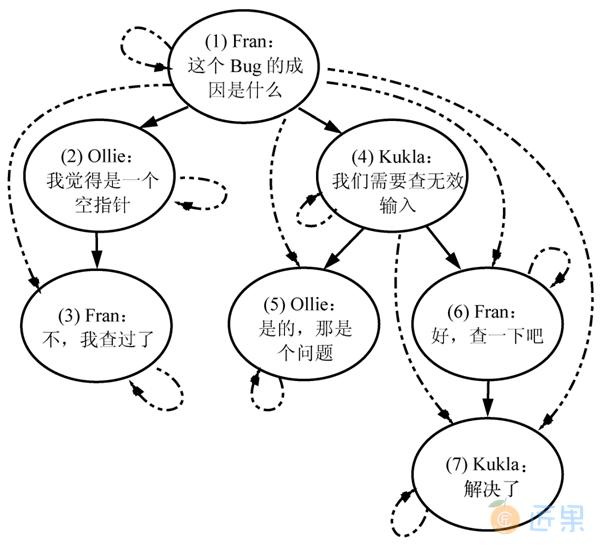
通过TreePaths表来获取祖先和后代比使用嵌套集更加地直接。例如要获取评论#4的后代,只需要在TreePaths表中搜索祖先是评论#4的行就可以了:
Trees/soln/closure-table/descendants.sql
SELECT c.* FROM Comments AS c
JOIN TreePaths AS t ON c.comment_id = t.descendant WHERE t.ancestor = 4;
要获取评论#6的所有祖先,只需要在TreePaths表中搜索后代为评论#6的行就可以了:
Trees/soln/closure-table/ancestors.sql
SELECT c.* FROM Comments AS c
JOIN TreePaths AS t ON c.comment_id = t.ancestor WHERE t.descendant = 6;
要插入一个新的叶子节点,比如评论#5的一个子节点,应首先插入一条自己到自己的关系,然后搜索TreePaths表中后代是评论#5的节点,增加该节点和新插入节点的“祖先—后代”关系(包括评论#5的自我引用):
Trees/soln/closure-table/insert.sql
INSERT INTO TreePaths (ancestor, descendant)
SELECT t.ancestor, 8
FROM TreePaths AS t
WHERE t.descendant = 5
UNION ALL SELECT 8, 8;
要删除一个叶子节点,比如评论#7,应删除所有TreePaths表中后代为评论#7的行:
Trees/soln/closure-table/delete-leaf.sql
DELETE FROM TreePaths WHERE descendant = 7;
要删除一棵完整的子树,比如评论#4和它所有的后代,可删除所有在TreePaths表中后代为#4的行,以及那些以评论#4的后代为后代的行:
Trees/soln/closure-table/delete-subtree.sql
DELETE FROM TreePaths WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = 4);
请注意,如果你删除了TreePahts中的一条记录,并不是真正删除了这条评论。这对于评论系统这个例子来说可能很奇怪,但它在其他类型的树形结构的设计中会变得比较有意义。比如在产品目录的分类或者员工组织架构的图表中,当你改变了节点关系的时候,并不是真地想要删除一个节点。我们把关系路径存储在一个分开独立的表中,使得设计更加灵活。
要从一个地方移动一棵子树到另一地方,首先要断开这棵子树和它的祖先们的关系,所需要做的就是找到这棵子树的顶点,删除它的所有子节点和它的所有祖先节点间的关系。比如将评论#6从它现在的位置(评论#4的孩子)移动到评论#3下,首先做如下的删除(确保别把评论#6的自我引用删掉)。
Trees/soln/closure-table/move-subtree.sql
DELETE FROM TreePaths WHERE descendant IN (SELECT descendant FROM TreePaths WHERE ancestor = 6)
AND ancestor IN (SELECT ancestor FROM TreePaths WHERE descendant = 6 AND ancestor != descendant);
查询评论#6的祖先(不包含评论#6自身),以及评论#6的后代(包括评论#6自身),然后删除它们之间的关系,这将正确地移除所有从评论#6的祖先到评论#6和它的后代之间的路径。换言之,这就删除了路径(1, 6)、(1,7)、(4, 6)和(4, 7),并且它不会删除(6, 6) 或 (6, 7)。
然后将这棵孤立的树和新节点及它的祖先建立关系。可以使用CROSS JOIN语句来创建一个新节点及其祖先和这棵孤立的树中所有节点间的笛卡儿积来建立所有需要的关系。
Trees/soln/closure-table/move-subtree.sql
INSERT INTO TreePaths (ancestor, descendant)
SELECT supertree.ancestor, subtree.descendant
FROM TreePaths AS supertree
CROSS JOIN TreePaths AS subtree
WHERE supertree.descendant = 3
AND subtree.ancestor = 6;
这样就创建了评论#3及它的所有祖先节点到评论#6及其所有后代之间的路径。因此,新的路径是:(1, 6)、(2, 6)、(3, 6)、(1, 7)、(2, 7)、(3, 7)。同时,评论#6为顶点的这棵子树就成为了评论#3的后代。笛卡儿积能创建所有需要的路径,即使这棵子树的层级在移动过程中发生了改变。
闭包表的设计比嵌套集更加地直接,两者都能快捷地查询给定节点的祖先和后代,但是闭包表能更加简单地维护分层信息。这两个设计都比使用邻接表或者路径枚举更方便地查询给定节
点的直接后代和父代。
然而,你可以优化闭包表来使它更方便地查询直接父亲节点或子节点:在TreePaths表中增加一个path_length字段。一个节点的自我引用的path_length为0,到它直接子节点的path_length为1,再下一层为2,以此类推。查询评论#4的子节点就变得很直接:
Trees/soln/closure-table/child.sql
SELECT * FROM TreePaths WHERE ancestor = 4 AND path_length = 1;
3.5.4 你该使用哪种设计
每种设计都各有优劣,如何选择设计依赖于应用程序中的哪种操作最需要性能上的优化。在图3-5中,操作依据每种树的设计被标记为简单或者困难。你也可以参考以下列出的每种设计的优缺点。

- 邻接表是最方便的设计,并且很多软件开发者都了解它。
- 如果你使用的数据库支持WITH或者CONNECT BY PRIOR的递归查询,那能使得邻接表的查询更为高效。
- 枚举路径能够很直观地展示出祖先到后代之间的路径,但同时由于它不能确保引用完整性,使得这个设计非常地脆弱。枚举路径也使得数据的存储变得比较冗余。
- 嵌套集是一个聪明的解决方案——但可能过于聪明了,它不能确保引用完整性。最好在一个查询性能要求很高而对其他需求要求一般的场合来使用它。
- 闭包表是最通用的设计,并且本章所描述的设计中只有它能允许一个节点属于多棵树。它要求一张额外的表来存储关系,使用空间换时间的方案减少操作过程中由冗余的计算所造成的消耗。
关于存储和操作SQL中的分层数据有很多东西可以说。Jeo Celko的Trees and Hierarchies in SQL for Smarties[Cel04]是一本介绍分层查询的好书,另一本讲解了树及图论的书是SQL Design Patterns[Tro06],作者是Vadim Tropashko。后者更加正规及理论化。
一个分层数据结构包含了数据项和它们之间的关系。需要合理的设计两者的模型来配合你的工作。
下一节:外面的生物从猪看到人,从人看到猪,再从猪看到人,但它们已经分辨不出谁是猪谁是人了。 -- 乔治·奥威尔,《动物庄园》