Ex1:口袋妖怪数据集
In [29]: df = pd.read_csv('data/pokemon.csv')
In [30]: (df[['HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed'
....: ]].sum(1)!=df['Total']).mean()
....:
Out[30]: 0.0
In [31]: dp_dup = df.drop_duplicates('#', keep='first')
In [32]: dp_dup['Type 1'].nunique()
Out[32]: 18
In [33]: dp_dup['Type 1'].value_counts().index[:3]
Out[33]: Index(['Water', 'Normal', 'Grass'], dtype='object')
In [34]: attr_dup = dp_dup.drop_duplicates(['Type 1', 'Type 2'])
In [35]: attr_dup.shape[0]
Out[35]: 143
In [36]: L_full = [i+' '+j if i!=j else i for i in df['Type 1'
....: ].unique() for j in df['Type 1'].unique()]
....:
In [37]: L_part = [i+' '+j if not isinstance(j, float) else i for i, j in zip(
....: df['Type 1'], df['Type 2'])]
....:
In [38]: res = set(L_full).difference(set(L_part))
In [39]: len(res) # 太多,不打印了
Out[39]: 170
In [40]: df['Attack'].mask(df['Attack']>120, 'high'
....: ).mask(df['Attack']<50, 'low').mask((50<=df['Attack']
....: )&(df['Attack']<=120), 'mid').head()
....:
Out[40]:
0 low
1 mid
2 mid
3 mid
4 mid
Name: Attack, dtype: object
In [41]: df['Type 1'].replace({i:str.upper(i) for i in df['Type 1'
....: ].unique()}).head()
....:
Out[41]:
0 GRASS
1 GRASS
2 GRASS
3 GRASS
4 FIRE
Name: Type 1, dtype: object
In [42]: df['Type 1'].apply(lambda x:str.upper(x)).head()
Out[42]:
0 GRASS
1 GRASS
2 GRASS
3 GRASS
4 FIRE
Name: Type 1, dtype: object
In [43]: df['Deviation'] = df[['HP', 'Attack', 'Defense', 'Sp. Atk',
....: 'Sp. Def', 'Speed']].apply(lambda x:np.max(
....: (x-x.median()).abs()), 1)
....:
In [44]: df.sort_values('Deviation', ascending=False).head()
Out[44]:
# Name Type 1 Type 2 Total HP Attack Defense Sp. Atk Sp. Def Speed Deviation
230 213 Shuckle Bug Rock 505 20 10 230 10 230 5 215.0
121 113 Chansey Normal NaN 450 250 5 5 35 105 50 207.5
261 242 Blissey Normal NaN 540 255 10 10 75 135 55 190.0
333 306 AggronMega Aggron Steel NaN 630 70 140 230 60 80 50 155.0
224 208 SteelixMega Steelix Steel Ground 610 75 125 230 55 95 30 145.0
Ex2:指数加权窗口
In [45]: np.random.seed(0)
In [46]: s = pd.Series(np.random.randint(-1,2,30).cumsum())
In [47]: s.ewm(alpha=0.2).mean().head()
Out[47]:
0 -1.000000
1 -1.000000
2 -1.409836
3 -1.609756
4 -1.725845
dtype: float64
In [48]: def ewm_func(x, alpha=0.2):
....: win = (1-alpha)**np.arange(x.shape[0])[::-1]
....: res = (win*x).sum()/win.sum()
....: return res
....:
In [49]: s.expanding().apply(ewm_func).head()
Out[49]:
0 -1.000000
1 -1.000000
2 -1.409836
3 -1.609756
4 -1.725845
dtype: float64
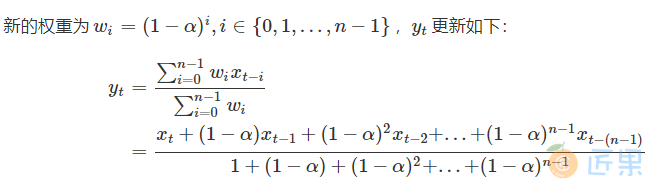
In [50]: s.rolling(window=4).apply(ewm_func).head() # 无需对原函数改动
Out[50]:
0 NaN
1 NaN
2 NaN
3 -1.609756
4 -1.826558
dtype: float64