1. Timestamp的构造与属性
单个时间戳的生成利用 pd.Timestamp 实现,一般而言的常见日期格式都能被成功地转换:
In [3]: ts = pd.Timestamp('2020/1/1')
In [4]: ts
Out[4]: Timestamp('2020-01-01 00:00:00')
In [5]: ts = pd.Timestamp('2020-1-1 08:10:30')
In [6]: ts
Out[6]: Timestamp('2020-01-01 08:10:30')
通过 year, month, day, hour, min, second 可以获取具体的数值:
In [7]: ts.year
Out[7]: 2020
In [8]: ts.month
Out[8]: 1
In [9]: ts.day
Out[9]: 1
In [10]: ts.hour
Out[10]: 8
In [11]: ts.minute
Out[11]: 10
In [12]: ts.second
Out[12]: 30
在 pandas 中,时间戳的最小精度为纳秒 ns ,由于使用了64位存储,可以表示的时间范围大约可以如下计算:
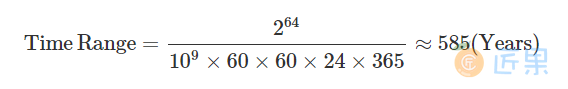
通过 pd.Timestamp.max 和 pd.Timestamp.min 可以获取时间戳表示的范围,可以看到确实表示的区间年数大小正如上述计算结果:
In [13]: pd.Timestamp.max
Out[13]: Timestamp('2262-04-11 23:47:16.854775807')
In [14]: pd.Timestamp.min
Out[14]: Timestamp('1677-09-21 00:12:43.145225')
In [15]: pd.Timestamp.max.year - pd.Timestamp.min.year
Out[15]: 585
2. Datetime序列的生成
一组时间戳可以组成时间序列,可以用 to_datetime 和 date_range 来生成。其中, to_datetime 能够把一列时间戳格式的对象转换成为 datetime64[ns] 类型的时间序列:
In [16]: pd.to_datetime(['2020-1-1', '2020-1-3', '2020-1-6'])
Out[16]: DatetimeIndex(['2020-01-01', '2020-01-03', '2020-01-06'], dtype='datetime64[ns]', freq=None)
In [17]: df = pd.read_csv('data/learn_pandas.csv')
In [18]: s = pd.to_datetime(df.Test_Date)
In [19]: s.head()
Out[19]:
0 2019-10-05
1 2019-09-04
2 2019-09-12
3 2020-01-03
4 2019-11-06
Name: Test_Date, dtype: datetime64[ns]
在极少数情况,时间戳的格式不满足转换时,可以强制使用 format 进行匹配:
In [20]: temp = pd.to_datetime(['2020\\1\\1','2020\\1\\3'],format='%Y\\%m\\%d')
In [21]: temp
Out[21]: DatetimeIndex(['2020-01-01', '2020-01-03'], dtype='datetime64[ns]', freq=None)
注意上面由于传入的是列表,而非 pandas 内部的 Series ,因此返回的是 DatetimeIndex ,如果想要转为 datetime64[ns] 的序列,需要显式用 Series 转化:
In [22]: pd.Series(temp).head()
Out[22]:
0 2020-01-01
1 2020-01-03
dtype: datetime64[ns]
另外,还存在一种把表的多列时间属性拼接转为时间序列的 to_datetime 操作,此时的列名必须和以下给定的时间关键词列名一致:
In [23]: df_date_cols = pd.DataFrame({'year': [2020, 2020],
....: 'month': [1, 1],
....: 'day': [1, 2],
....: 'hour': [10, 20],
....: 'minute': [30, 50],
....: 'second': [20, 40]})
....:
In [24]: pd.to_datetime(df_date_cols)
Out[24]:
0 2020-01-01 10:30:20
1 2020-01-02 20:50:40
dtype: datetime64[ns]
date_range 是一种生成连续间隔时间的一种方法,其重要的参数为 start, end, freq, periods ,它们分别表示开始时间,结束时间,时间间隔,时间戳个数。其中,四个中的三个参数决定了,那么剩下的一个就随之确定了。这里要注意,开始或结束日期如果作为端点则它会被包含:
In [25]: pd.date_range('2020-1-1','2020-1-21', freq='10D') # 包含
Out[25]: DatetimeIndex(['2020-01-01', '2020-01-11', '2020-01-21'], dtype='datetime64[ns]', freq='10D')
In [26]: pd.date_range('2020-1-1','2020-2-28', freq='10D')
Out[26]:
DatetimeIndex(['2020-01-01', '2020-01-11', '2020-01-21', '2020-01-31',
'2020-02-10', '2020-02-20'],
dtype='datetime64[ns]', freq='10D')
In [27]: pd.date_range('2020-1-1',
....: '2020-2-28', periods=6) # 由于结束日期无法取到,freq不为10天
....:
Out[27]:
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-12 14:24:00',
'2020-01-24 04:48:00', '2020-02-04 19:12:00',
'2020-02-16 09:36:00', '2020-02-28 00:00:00'],
dtype='datetime64[ns]', freq=None)
这里的 freq 参数与 DateOffset 对象紧密相关,将在第四节介绍其具体的用法。
练一练
Timestamp上定义了一个value属性,其返回的整数值代表了从1970年1月1日零点到给定时间戳相差的纳秒数,请利用这个属性构造一个随机生成给定日期区间内日期序列的函数。
最后,要介绍一种改变序列采样频率的方法 asfreq ,它能够根据给定的 freq 对序列进行类似于 reindex 的操作:
In [28]: s = pd.Series(np.random.rand(5),
....: index=pd.to_datetime([
....: '2020-1-%d'%i for i in range(1,10,2)]))
....:
In [29]: s.head()
Out[29]:
2020-01-01 0.836578
2020-01-03 0.678419
2020-01-05 0.711897
2020-01-07 0.487429
2020-01-09 0.604705
dtype: float64
In [30]: s.asfreq('D').head()
Out[30]:
2020-01-01 0.836578
2020-01-02 NaN
2020-01-03 0.678419
2020-01-04 NaN
2020-01-05 0.711897
Freq: D, dtype: float64
In [31]: s.asfreq('12H').head()
Out[31]:
2020-01-01 00:00:00 0.836578
2020-01-01 12:00:00 NaN
2020-01-02 00:00:00 NaN
2020-01-02 12:00:00 NaN
2020-01-03 00:00:00 0.678419
Freq: 12H, dtype: float64
datetime64[ns]序列的最值与均值
前面提到了
datetime64[ns]本质上可以理解为一个大整数,对于一个该类型的序列,可以使用max, min, mean,来取得最大时间戳、最小时间戳和“平均”时间戳。
3. dt对象
如同 category, string 的序列上定义了 cat, str 来完成分类数据和文本数据的操作,在时序类型的序列上定义了 dt 对象来完成许多时间序列的相关操作。这里对于 datetime64[ns] 类型而言,可以大致分为三类操作:取出时间相关的属性、判断时间戳是否满足条件、取整操作。
第一类操作的常用属性包括: date, time, year, month, day, hour, minute, second, microsecond, nanosecond, dayofweek, dayofyear, weekofyear, daysinmonth, quarter ,其中 daysinmonth, quarter 分别表示该月一共有几天和季度。
In [32]: s = pd.Series(pd.date_range('2020-1-1','2020-1-3', freq='D'))
In [33]: s.dt.date
Out[33]:
0 2020-01-01
1 2020-01-02
2 2020-01-03
dtype: object
In [34]: s.dt.time
Out[34]:
0 00:00:00
1 00:00:00
2 00:00:00
dtype: object
In [35]: s.dt.day
Out[35]:
0 1
1 2
2 3
dtype: int64
In [36]: s.dt.daysinmonth
Out[36]:
0 31
1 31
2 31
dtype: int64
在这些属性中,经常使用的是 dayofweek ,它返回了周中的星期情况,周一为0、周二为1,以此类推:
In [37]: s.dt.dayofweek
Out[37]:
0 2
1 3
2 4
dtype: int64
此外,可以通过 month_name, day_name 返回英文的月名和星期名,注意它们是方法而不是属性:
In [38]: s.dt.month_name()
Out[38]:
0 January
1 January
2 January
dtype: object
In [39]: s.dt.day_name()
Out[39]:
0 Wednesday
1 Thursday
2 Friday
dtype: object
第二类判断操作主要用于测试是否为月/季/年的第一天或者最后一天:
In [40]: s.dt.is_year_start # 还可选 is_quarter/month_start
Out[40]:
0 True
1 False
2 False
dtype: bool
In [41]: s.dt.is_year_end # 还可选 is_quarter/month_end
Out[41]:
0 False
1 False
2 False
dtype: bool
第三类的取整操作包含 round, ceil, floor ,它们的公共参数为 freq ,常用的包括 H, min, S (小时、分钟、秒),所有可选的 freq 可参考 此处 。
In [42]: s = pd.Series(pd.date_range('2020-1-1 20:35:00',
....: '2020-1-1 22:35:00',
....: freq='45min'))
....:
In [43]: s
Out[43]:
0 2020-01-01 20:35:00
1 2020-01-01 21:20:00
2 2020-01-01 22:05:00
dtype: datetime64[ns]
In [44]: s.dt.round('1H')
Out[44]:
0 2020-01-01 21:00:00
1 2020-01-01 21:00:00
2 2020-01-01 22:00:00
dtype: datetime64[ns]
In [45]: s.dt.ceil('1H')
Out[45]:
0 2020-01-01 21:00:00
1 2020-01-01 22:00:00
2 2020-01-01 23:00:00
dtype: datetime64[ns]
In [46]: s.dt.floor('1H')
Out[46]:
0 2020-01-01 20:00:00
1 2020-01-01 21:00:00
2 2020-01-01 22:00:00
dtype: datetime64[ns]
4. 时间戳的切片与索引
一般而言,时间戳序列作为索引使用。如果想要选出某个子时间戳序列,第一类方法是利用 dt 对象和布尔条件联合使用,另一种方式是利用切片,后者常用于连续时间戳。下面,举一些例子说明:
In [47]: s = pd.Series(np.random.randint(2,size=366),
....: index=pd.date_range(
....: '2020-01-01','2020-12-31'))
....:
In [48]: idx = pd.Series(s.index).dt
In [49]: s.head()
Out[49]:
2020-01-01 1
2020-01-02 1
2020-01-03 0
2020-01-04 1
2020-01-05 0
Freq: D, dtype: int32
Example1:每月的第一天或者最后一天
In [50]: s[(idx.is_month_start|idx.is_month_end).values].head()
Out[50]:
2020-01-01 1
2020-01-31 0
2020-02-01 1
2020-02-29 1
2020-03-01 0
dtype: int32
Example2:双休日
In [51]: s[idx.dayofweek.isin([5,6]).values].head()
Out[51]:
2020-01-04 1
2020-01-05 0
2020-01-11 0
2020-01-12 1
2020-01-18 1
dtype: int32
Example3:取出单日值
In [52]: s['2020-01-01']
Out[52]: 1
In [53]: s['20200101'] # 自动转换标准格式
Out[53]: 1
Example4:取出七月
In [54]: s['2020-07'].head()
Out[54]:
2020-07-01 0
2020-07-02 1
2020-07-03 0
2020-07-04 0
2020-07-05 0
Freq: D, dtype: int32
Example5:取出5月初至7月15日
In [55]: s['2020-05':'2020-7-15'].head()
Out[55]:
2020-05-01 0
2020-05-02 1
2020-05-03 0
2020-05-04 1
2020-05-05 1
Freq: D, dtype: int32
In [56]: s['2020-05':'2020-7-15'].tail()
Out[56]:
2020-07-11 0
2020-07-12 0
2020-07-13 1
2020-07-14 0
2020-07-15 1
Freq: D, dtype: int32