1. apply的引入
之前几节介绍了三大分组操作,但事实上还有一种常见的分组场景,无法用前面介绍的任何一种方法处理,例如现在如下定义身体质量指数BMI:
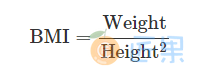
其中体重和身高的单位分别为千克和米,需要分组计算组BMI的均值。
首先,这显然不是过滤操作,因此 filter 不符合要求;其次,返回的均值是标量而不是序列,因此 transform 不符合要求;最后,似乎使用 agg 函数能够处理,但是之前强调过聚合函数是逐列处理的,而不能够 多列数据同时处理 。由此,引出了 apply 函数来解决这一问题。
2. apply的使用
在设计上, apply 的自定义函数传入参数与 filter 完全一致,只不过后者只允许返回布尔值。现如下解决上述计算问题:
In [38]: def BMI(x):
....: Height = x['Height']/100
....: Weight = x['Weight']
....: BMI_value = Weight/Height**2
....: return BMI_value.mean()
....:
In [39]: gb.apply(BMI)
Out[39]:
Gender
Female 18.860930
Male 24.318654
dtype: float64
除了返回标量之外, apply 方法还可以返回一维 Series 和二维 DataFrame ,但它们产生的数据框维数和多级索引的层数应当如何变化?下面举三组例子就非常容易明白结果是如何生成的:
【a】标量情况:结果得到的是 Series ,索引与 agg 的结果一致
In [40]: gb = df.groupby(['Gender','Test_Number'])[['Height','Weight']]
In [41]: gb.apply(lambda x: 0)
Out[41]:
Gender Test_Number
Female 1 0
2 0
3 0
Male 1 0
2 0
3 0
dtype: int64
In [42]: gb.apply(lambda x: [0, 0]) # 虽然是列表,但是作为返回值仍然看作标量
Out[42]:
Gender Test_Number
Female 1 [0, 0]
2 [0, 0]
3 [0, 0]
Male 1 [0, 0]
2 [0, 0]
3 [0, 0]
dtype: object
【b】 Series 情况:得到的是 DataFrame ,行索引与标量情况一致,列索引为 Series 的索引
In [43]: gb.apply(lambda x: pd.Series([0,0],index=['a','b']))
Out[43]:
a b
Gender Test_Number
Female 1 0 0
2 0 0
3 0 0
Male 1 0 0
2 0 0
3 0 0
练一练
请尝试在
apply传入的自定义函数中,根据组的某些特征返回相同长度但索引不同的Series,会报错吗?
【c】 DataFrame 情况:得到的是 DataFrame ,行索引最内层在每个组原先 agg 的结果索引上,再加一层返回的 DataFrame 行索引,同时分组结果 DataFrame 的列索引和返回的 DataFrame 列索引一致。
In [44]: gb.apply(lambda x: pd.DataFrame(np.ones((2,2)),
....: index = ['a','b'],
....: columns=pd.Index([('w','x'),('y','z')])))
....:
Out[44]:
w y
x z
Gender Test_Number
Female 1 a 1.0 1.0
b 1.0 1.0
2 a 1.0 1.0
b 1.0 1.0
3 a 1.0 1.0
b 1.0 1.0
Male 1 a 1.0 1.0
b 1.0 1.0
2 a 1.0 1.0
b 1.0 1.0
3 a 1.0 1.0
b 1.0 1.0
练一练
请尝试在
apply传入的自定义函数中,根据组的某些特征返回相同大小但列索引不同的DataFrame,会报错吗?如果只是行索引不同,会报错吗?
最后需要强调的是, apply 函数的灵活性是以牺牲一定性能为代价换得的,除非需要使用跨列处理的分组处理,否则应当使用其他专门设计的 groupby 对象方法,否则在性能上会存在较大的差距。同时,在使用聚合函数和变换函数时,也应当优先使用内置函数,它们经过了高度的性能优化,一般而言在速度上都会快于用自定义函数来实现。
练一练
在
groupby对象中还定义了cov和corr函数,从概念上说也属于跨列的分组处理。请利用之前定义的gb对象,使用apply函数实现与gb.cov()同样的功能并比较它们的性能。