1. 集合的运算法则
经常会有一种利用集合运算来取出符合条件行的需求,例如有两张表 A 和 B ,它们的索引都是员工编号,现在需要筛选出两表索引交集的所有员工信息,此时通过 Index 上的运算操作就很容易实现。
不过在此之前,不妨先复习一下常见的四种集合运算:
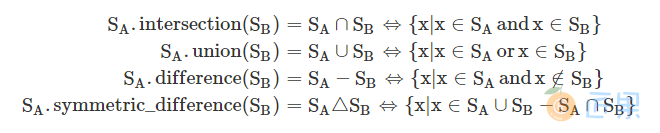
2. 一般的索引运算
由于集合的元素是互异的,但是索引中可能有相同的元素,先用 unique 去重后再进行运算。下面构造两张最为简单的示例表进行演示:
In [166]: df_set_1 = pd.DataFrame([[0,1],[1,2],[3,4]],
.....: index = pd.Index(['a','b','a'],name='id1'))
.....:
In [167]: df_set_2 = pd.DataFrame([[4,5],[2,6],[7,1]],
.....: index = pd.Index(['b','b','c'],name='id2'))
.....:
In [168]: id1, id2 = df_set_1.index.unique(), df_set_2.index.unique()
In [169]: id1.intersection(id2)
Out[169]: Index(['b'], dtype='object')
In [170]: id1.union(id2)
Out[170]: Index(['a', 'b', 'c'], dtype='object')
In [171]: id1.difference(id2)
Out[171]: Index(['a'], dtype='object')
In [172]: id1.symmetric_difference(id2)
Out[172]: Index(['a', 'c'], dtype='object')
若两张表需要做集合运算的列并没有被设置索引,一种办法是先转成索引,运算后再恢复,另一种方法是利用 isin 函数,例如在重置索引的第一张表中选出id列交集的所在行:
In [173]: df_set_in_col_1 = df_set_1.reset_index()
In [174]: df_set_in_col_2 = df_set_2.reset_index()
In [175]: df_set_in_col_1
Out[175]:
id1 0 1
0 a 0 1
1 b 1 2
2 a 3 4
In [176]: df_set_in_col_2
Out[176]:
id2 0 1
0 b 4 5
1 b 2 6
2 c 7 1
In [177]: df_set_in_col_1[df_set_in_col_1.id1.isin(df_set_in_col_2.id2)]
Out[177]:
id1 0 1
1 b 1 2